
"The first computer we had was a Commodore 64C that we got quite probably in 1989, when I was 4 years old, from my mom's coworker, when their kid upgraded to an Amiga. I remember all the games I played on my first computer fondly."
And what awesome stories those are. Nothing beats the first computer. Except - the second computer of course. And this is a story about that 2nd, which for me reads like this:
"The second computer we had was a 'MikroMikko'-branded 16 MHz Intel 386SX PC, which had 2MB of RAM, and a 20MB hard drive. My mom bought it most likely in the summer of 1990, for a price of ~16000 Finnish Marks, and all my friends came over to play on it."
The MikroMikko computer was manufactured by Nokia, that company that once manufactured cell phones. In its history, Nokia has built all sorts of things, including rubber boots (which it still does), TVs, and also computers. The computer product brand was called "MikroMikko", and it operated until 1991 when it was sold off to the British company ICL.
I recall the MikroMikko very vividly, maybe even more so than the C64, because the MikroMikko was the PC that I learned programming with (C64 for me was just for games). While I still have that original C64 (which I've restored in the past years), the MikroMikko PC we had was quite likely given away around 1994-1996 when we got a 120 MHz "Pomi" Pentium PC.
For a long while I had felt sad over the memory of that lost great and powerful PC we once had. In December anno Covid quarantine of 2020, by some Christmas miracle, I happened to stumble upon a listing on the Finnish site Huuto.net, where a remarkably complete looking package of an original MikroMikko 4TT m326 was being auctioned. All the technical specifications and visual appearance seemed to match exactly to what my memory told me (with the exception that the HDD was a 40MB one, even though I could swear ours was a 20MB model), so I knew I had to grab that. A somewhat heated bid war later, and 405,05€ + 35€ shipping lighter, this was a reality.
The next summer I spent a lot of time cleaning, restoring, tuning and upgrading it, and fast forward to today, December 2022, here is what it looks like:
The Borland Turbo C++ box that you see here contains the first compiler that I learned to use. My mom had attended a course on C++ programming in a local adult education center when all the municipality offices were being computerized. From that course she had brought home 3.5" floppy disks that contained "backup" copies of the Borland Turbo C++ 3.0 compiler that were distributed to all course attendees. (yeah, imagine how that sounds like today :D). Of course I got curious what it was that those disks contained.
I recall having the book "Opeta Itsellesi C++ -ohjelmointi" (Teach Yourself C++ Programming) back then to learn about all the basics of C++, which was the first language I approached. (yeah, I didn't start with Basic or x86 Assembly, like many others did).

In January this year I found a decently priced listing on eBay of the Borland compiler and went for it. You can imagine the wave of nostalgia I felt when I actually was able to install that first compiler from authentic floppy disks, and boot up the IDE first time in more than 25 years! What a walk back to the past! With this setup, I have been able to recompile my old code, play around with VGA mode 13h and learn a lot about the hardware that I never quite were able to master back then.
Now finally, come December of 2022, some coworkers are talking about attending Advent of Code again. I knew of AoC, but hadn't participated before, but somehow this time, that 1+1 just clicked. I couldn't resist. :) This would be a perfect opportunity to revisit my first steps when I was learning programming!
I decided that I would try to solve every puzzle by programming them directly on the MikroMikko using the Borland Turbo C++ 3.0 IDE. I also decided that I would actually record the process on video on Twitch. Although here I do say that I am not at all a streamer, so the content quality is not at all good. Maybe towards the end the videos did get a bit better, although most of the time it is bad audio levels, incoherent trains of thought, or me mumbling inaudibly, or waiting for the slowcarefully diligent PC to compile. This was more for archivation value than entertainment purposes.
Some of the targets for this challenge are as follows:
But before we can get to code, I need to make sure that the PC is actually ready to tackle the upcoming challenge. xD
 Here is what the MikroMikko internals look like. There is quite a bit of custom hardware design going on, and this PC does not follow any kind of standard XT or AT PC case or PSU layout. There is an ISA backplane sitting flat at the bottom, and then a large full length "CPU+RAM card" is connected to one of the ISA slots. There is a Finnish saying about "Nokia engineers", but this time it is literal.
Here is what the MikroMikko internals look like. There is quite a bit of custom hardware design going on, and this PC does not follow any kind of standard XT or AT PC case or PSU layout. There is an ISA backplane sitting flat at the bottom, and then a large full length "CPU+RAM card" is connected to one of the ISA slots. There is a Finnish saying about "Nokia engineers", but this time it is literal.
 The CPU+RAM card even stacks another smaller card on top of it, where the CPU itself resides. Who came up with this design! :D Also apologies for not blurring out the blue botch wires you see at the bottom. Err, let's just look to the left of it instead shall we, is that a ...?
The CPU+RAM card even stacks another smaller card on top of it, where the CPU itself resides. Who came up with this design! :D Also apologies for not blurring out the blue botch wires you see at the bottom. Err, let's just look to the left of it instead shall we, is that a ...?
 ... yes, it is! Originally when I bought this from the auction, it did not have an FPU, but there was an empty socket that was just calling for it. So I got one! A 16 MHz 387SX math coprocessor to go along with the 16 MHz 386SX CPU. How neat! Although I don't expect that the FPU will be used during Advent of Code, since floating point computation rarely makes for good puzzles. Nevertheless, really could not go without having one.
... yes, it is! Originally when I bought this from the auction, it did not have an FPU, but there was an empty socket that was just calling for it. So I got one! A 16 MHz 387SX math coprocessor to go along with the 16 MHz 386SX CPU. How neat! Although I don't expect that the FPU will be used during Advent of Code, since floating point computation rarely makes for good puzzles. Nevertheless, really could not go without having one.
Anticipating that me and Mr Mikko will be working hard hours and long shifts on the puzzles, taking care of stability is of utmost importance.
 I replaced the old loud case fan with a newer Noctua fan, which fits the color of this PC perfectly. I <3 Noctua. In front of the fan you can see the exotic PSU connector that the MikroMikko motherboard design sports.
I replaced the old loud case fan with a newer Noctua fan, which fits the color of this PC perfectly. I <3 Noctua. In front of the fan you can see the exotic PSU connector that the MikroMikko motherboard design sports.
 One of the scarier things about this vintage PC with respect to repairability is that it has a completely custom PSU design.
One of the scarier things about this vintage PC with respect to repairability is that it has a completely custom PSU design.
 When assembled, it sits on top of the PSU connector like above.
When assembled, it sits on top of the PSU connector like above.
 The PSU had been sealed shut with pop rivets. How rude :( Fortunately my cousin was able to take it carefully apart, and build new screw threads in their place. The internals of the PSU are well in order, what a relief.
The PSU had been sealed shut with pop rivets. How rude :( Fortunately my cousin was able to take it carefully apart, and build new screw threads in their place. The internals of the PSU are well in order, what a relief.
 I replaced the rivets with some nylon screws, which hold the PSU safely in place while being easier to service.
I replaced the rivets with some nylon screws, which hold the PSU safely in place while being easier to service.
 The original HDD is still there and functional, although now disconnected, and it will stand out on this one. When I later get back to tending to this HDD, I did glue some sticker labels to the hard drive so I don't forget in the future what the needed C/H/S values are.
The original HDD is still there and functional, although now disconnected, and it will stand out on this one. When I later get back to tending to this HDD, I did glue some sticker labels to the hard drive so I don't forget in the future what the needed C/H/S values are.
 For general use, I added an XT-IDE adapter along with a 512MB Compact Flash card to serve as the hard drive. For whatever reason, the MikroMikko BIOS itself did not recognize CF-based hard disks so an adapter was necessary here.
For general use, I added an XT-IDE adapter along with a 512MB Compact Flash card to serve as the hard drive. For whatever reason, the MikroMikko BIOS itself did not recognize CF-based hard disks so an adapter was necessary here.
 The CF card sticks out from the back quite nicely and easily accessible, if I ever need to write large amounts of data to it from another PC.
The CF card sticks out from the back quite nicely and easily accessible, if I ever need to write large amounts of data to it from another PC.
 The original battery did no longer hold time which required me to re-enter the HDD Cylinders/Heads/Sectors configuration again on each boot. We can't have that! A new battery fixed the issue right up.
The original battery did no longer hold time which required me to re-enter the HDD Cylinders/Heads/Sectors configuration again on each boot. We can't have that! A new battery fixed the issue right up.

As a finishing touch, I took the PC to a locksmith to get a new Abloy locking mechanism for the case. The sensitive reindeer data the Elves have is now guaranteed to be safe!

Note that these logs are not a tutorial of how to solve the different problems, this log is focused around aspects of vintage computing. It is still very spoiler heavy.
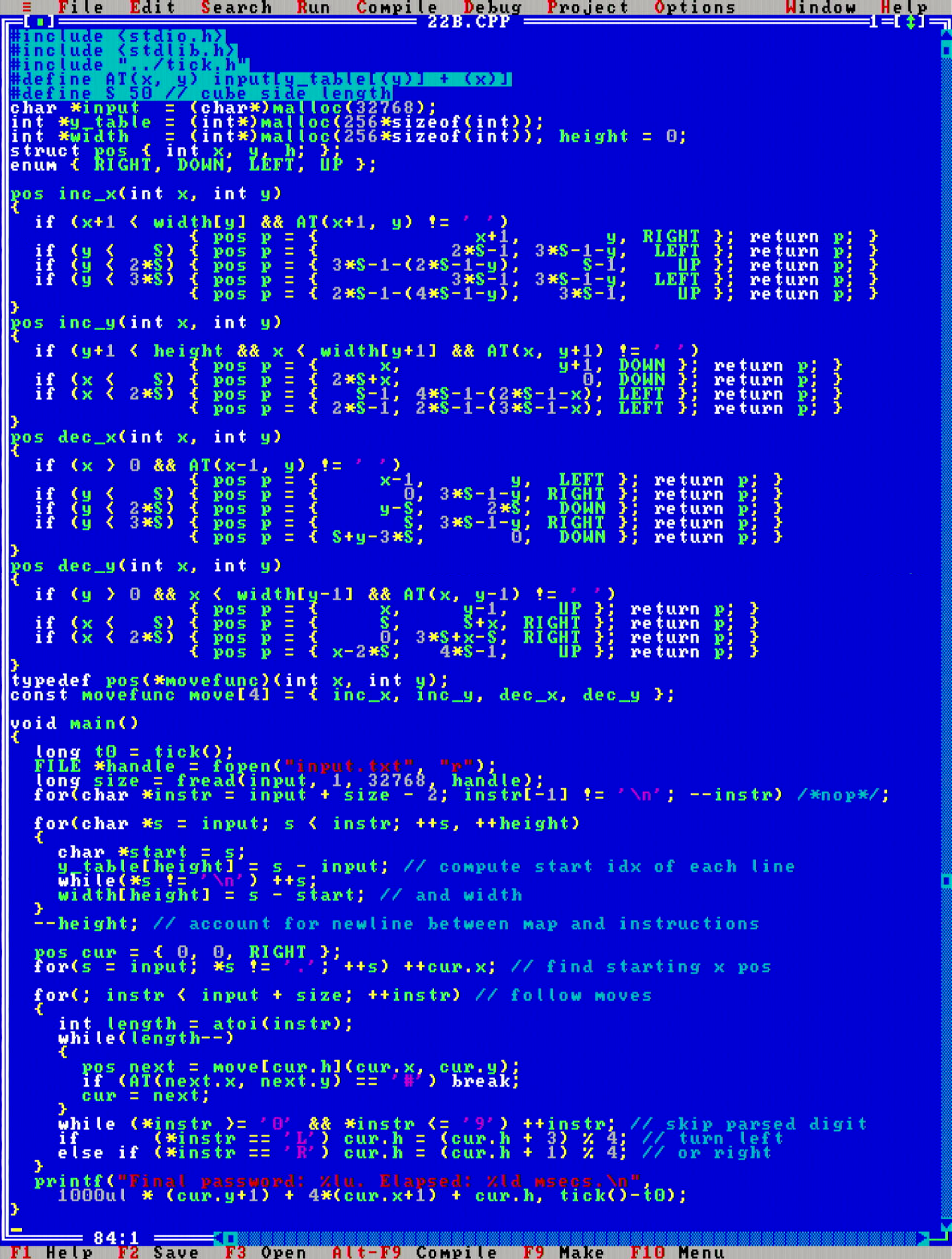
In the first part of the problem, the task was to find the maximum element from a list (well, a list of lists, where the sub-lists were summed together). This is done nicely in Θ(n) time and Θ(1) space in a one pass search through the input array. At the very first stretches, I thought that disk access would be really slow on the MikroMikko, so I immediately opted to implement a function read_file_to_string(const char *filename), which first reads the whole input file in memory in one fread() call to trade Θ(1) space to Θ(n) space for some practical batching efficiency - thinking that multiple fread() calls would be slow.
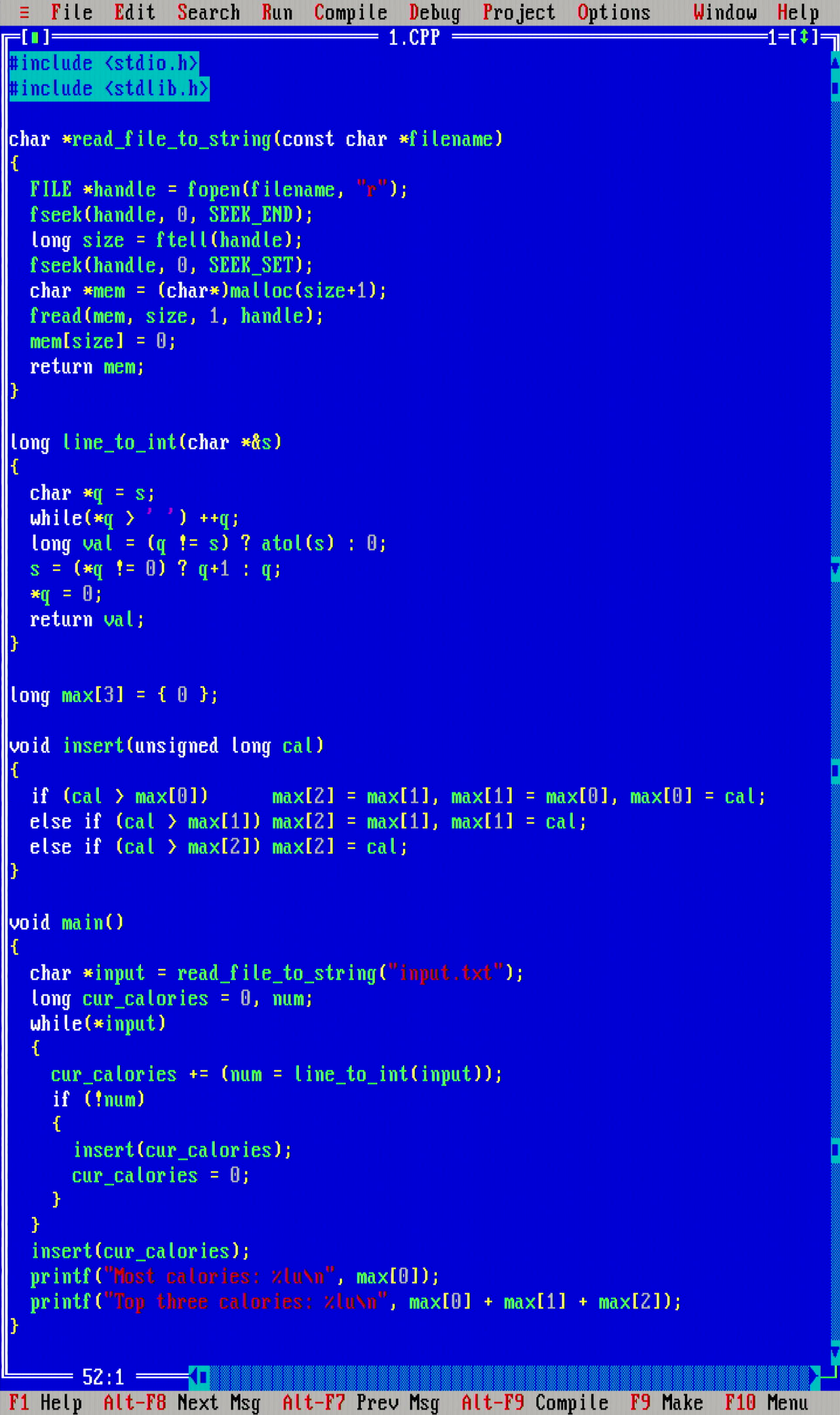
Don't you just love the 16-color CGA color scheme?
In the second part, the task was to find the sum of the calories from three elves who carry the most calories. Borrowing from the inner loop of how insertion search is implemented retains a nice optimal Θ(n) time and Θ(1) space runtime. No need to fill all elements into a data structure and then sort them, which would typically be a Θ(n*logn) operation.
I spent a LOT of time in the second part debugging a programming bug, which was due to 16-bit integer overflow. Borland Turbo C++ 3.0 is a compiler from the 8088/286 era and not actually a 386 compiler, so the int data type is still 16-bits in size and not 32-bit like it is on modern compilers. (there is no support for 64-bit integers either) This is something I knew from before and should have known while doing the puzzle, but somehow I just didn't connect the dots.
While writing the first puzzle, I was deeply saddened to realize that there is some kind of issue with the keyboard BIOS code on the MikroMikko: it is not possible to select text by holding down the shift key and dragging the cursor with the arrow keys. Instead, one must hold down the shift key and then use the Numpad arrows for text select to work. This is really awkward, but hopefully I will get used to this. (debugged this to not be a keyboard N-Key Rollover issue, but multiple keyboards behave the same on this PC, even though they work on other PCs)
Twitch.tv video link. Solve time: 1 hour 19 minutes. Runtime: 503 msecs.
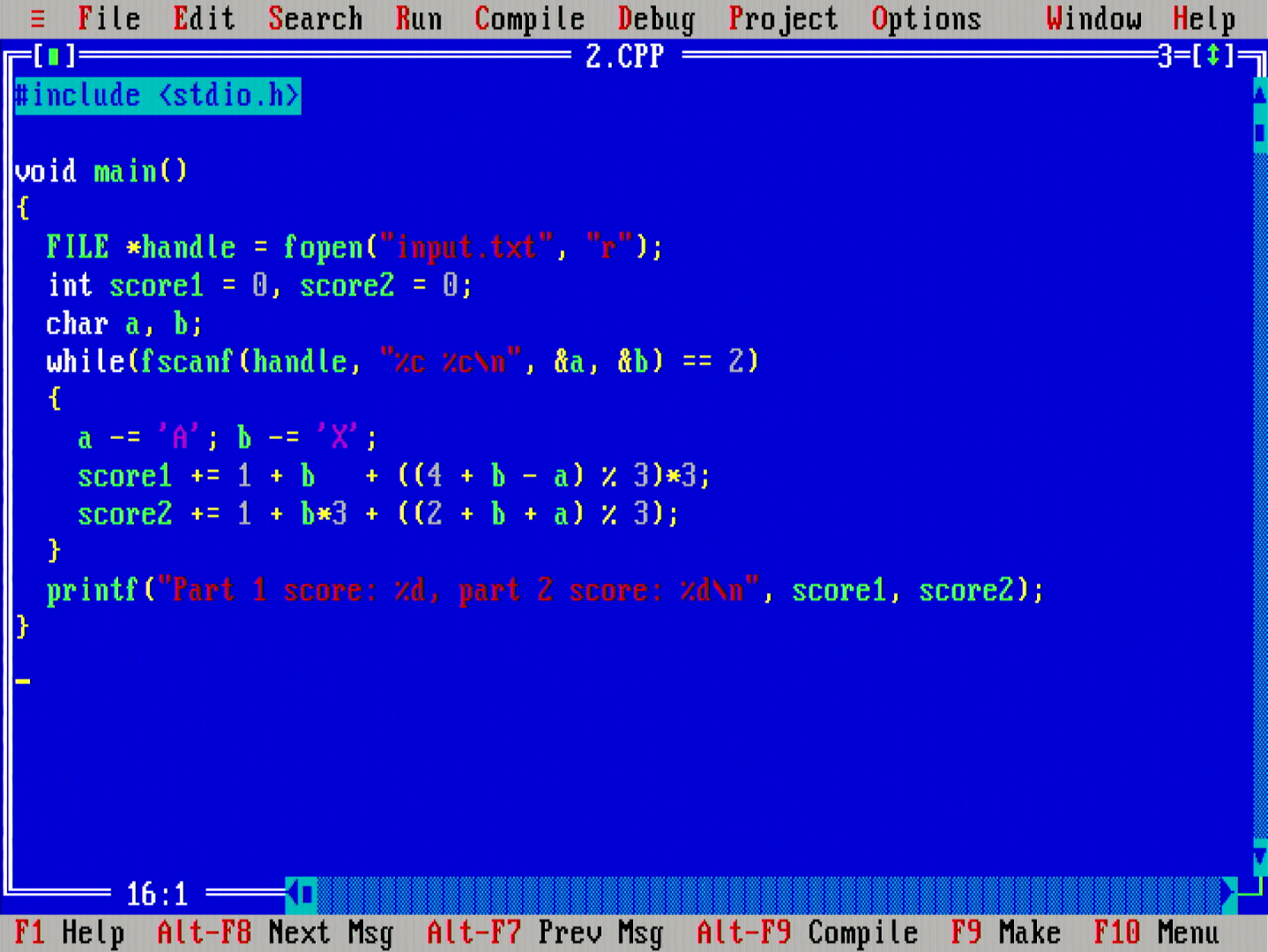
The first problem on the second day is to implement logic for rock-paper-scissors, and to compute a number of game results given sets of inputs. Quite easy in Θ(n) time and Θ(1) space.
The second problem for the day was very similar to the first, but it mixed up the logic a bit to give a pause - "What wins against rock?" - How confusing can such a simple question be? :D
Here is what my final cleaned up code looks like. It is a bit different from the code on the stream since I spent some time refactoring it afterwards, but maybe a sign of things to come: I am *not* code golfing, but can't resist being dirty like this! All sorts of unchecked assumptions abound, I love it :D
Twitch.tv video link. Solve time: 42 min 32 seconds. Runtime: 889 msecs.
On the third day puzzle, the elves are being idiots and the MikroMikko's job is to fix up after someone screwed up. I absolutely loved this AI generated photo from u/Iain_M_Norman on reddit.
 Since I am transferring all input data on a floppy, I wanted to print that image as a label for my AoC floppy disk, something like above, but unfortunately my label printer is all dried up of ink. Maybe the elves must have messed about on my printer as well. New ink cartridges are costly, so, maybe I'll print a label the next time I have something else I need to print too.
Since I am transferring all input data on a floppy, I wanted to print that image as a label for my AoC floppy disk, something like above, but unfortunately my label printer is all dried up of ink. Maybe the elves must have messed about on my printer as well. New ink cartridges are costly, so, maybe I'll print a label the next time I have something else I need to print too.
Two things I find today is that I am still spending a bit time to figure out what is the simplest way to parse input with libc, and also how to get familiar with the Turbo C++ IDE. Both aspects will be sure to improve.
Third day puzzle is about finding a single common character in two strings, or a common character in three strings.
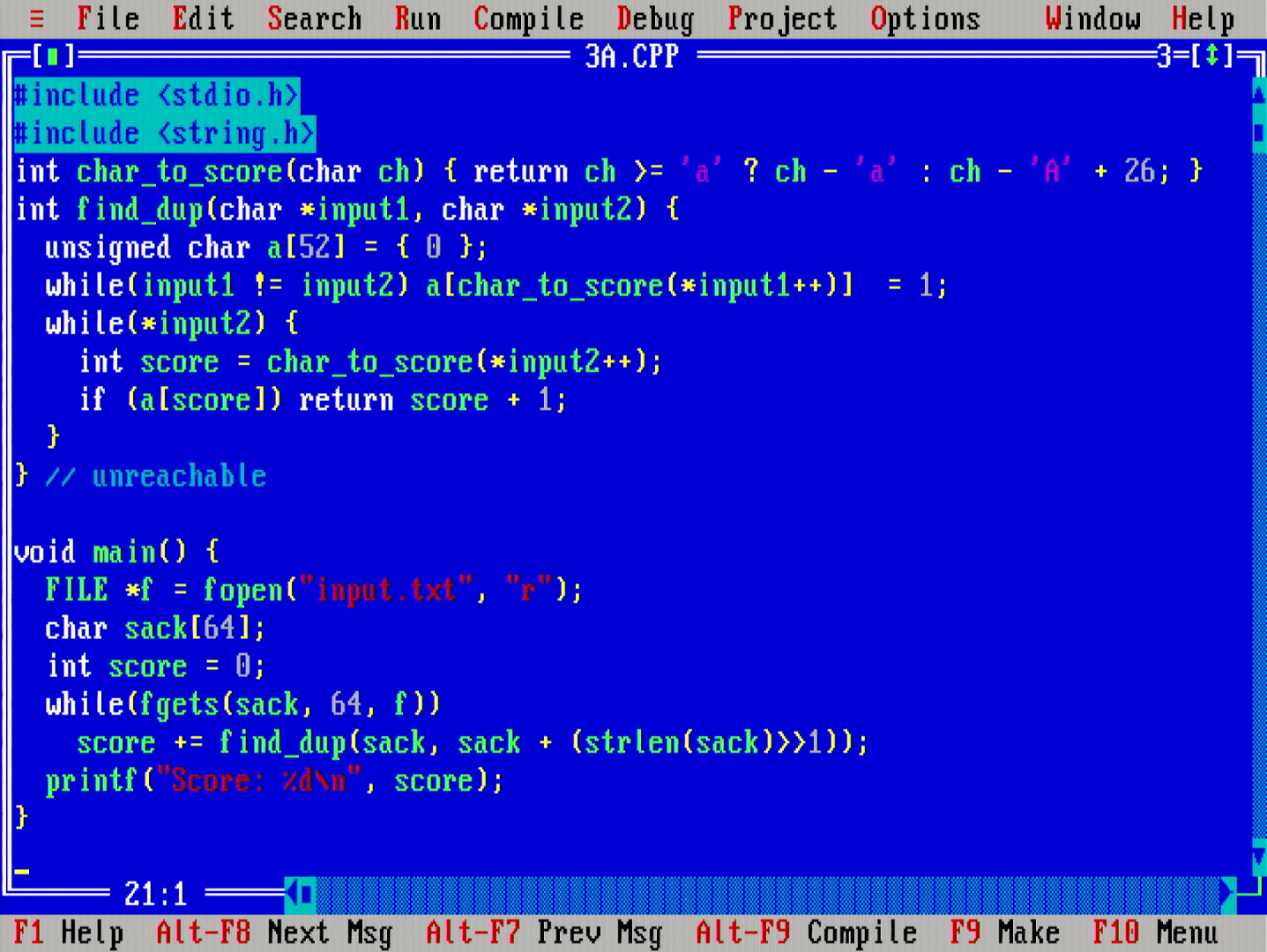
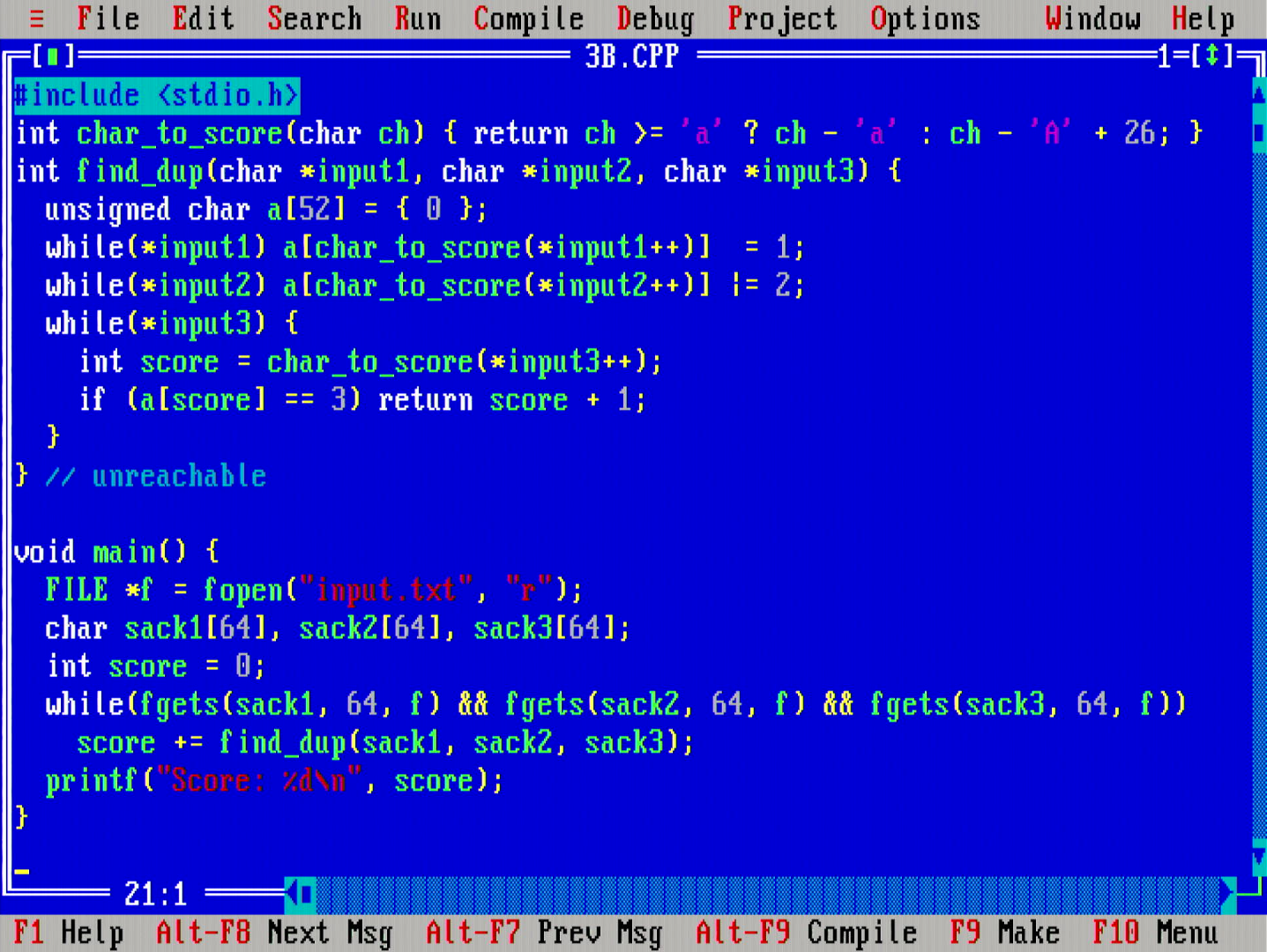
The code I finally settled on looks like the above. The problem is solved in Θ(n+|A|) time and Θ(|A|) space, where A is the alphabet the strings are from. The search loop is tight, and early outs from the inner loop immediately when possible. No feeding the strings to a (hash) set, or doing general set intersection operations, or anything like that.
Sidenote: MODE CON RATE=32 DELAY=1 ftw, typing without anything else than the fastest character repeat rate in DOS is a pain. (well, that is kind of the same on modern OSes a well)
Twitch.tv video links: part 1, part 2. Solve time: 51 min 30 seconds. Runtime: part 1: 403 msecs, part 2: 395 msecs.
This day was an absolute mess! In this puzzle, there were lines containing pairs of ranges, and the question was whether these range pairs would either intersect or be contained in one another. I completely misunderstood the problem, thinking that one would need to globally compute intersection across all ranges in the input file (not just the two), so I spent almost 20 minutes implementing a sort-and-sweep algorithm. After understanding that mixup, it was an easy problem.
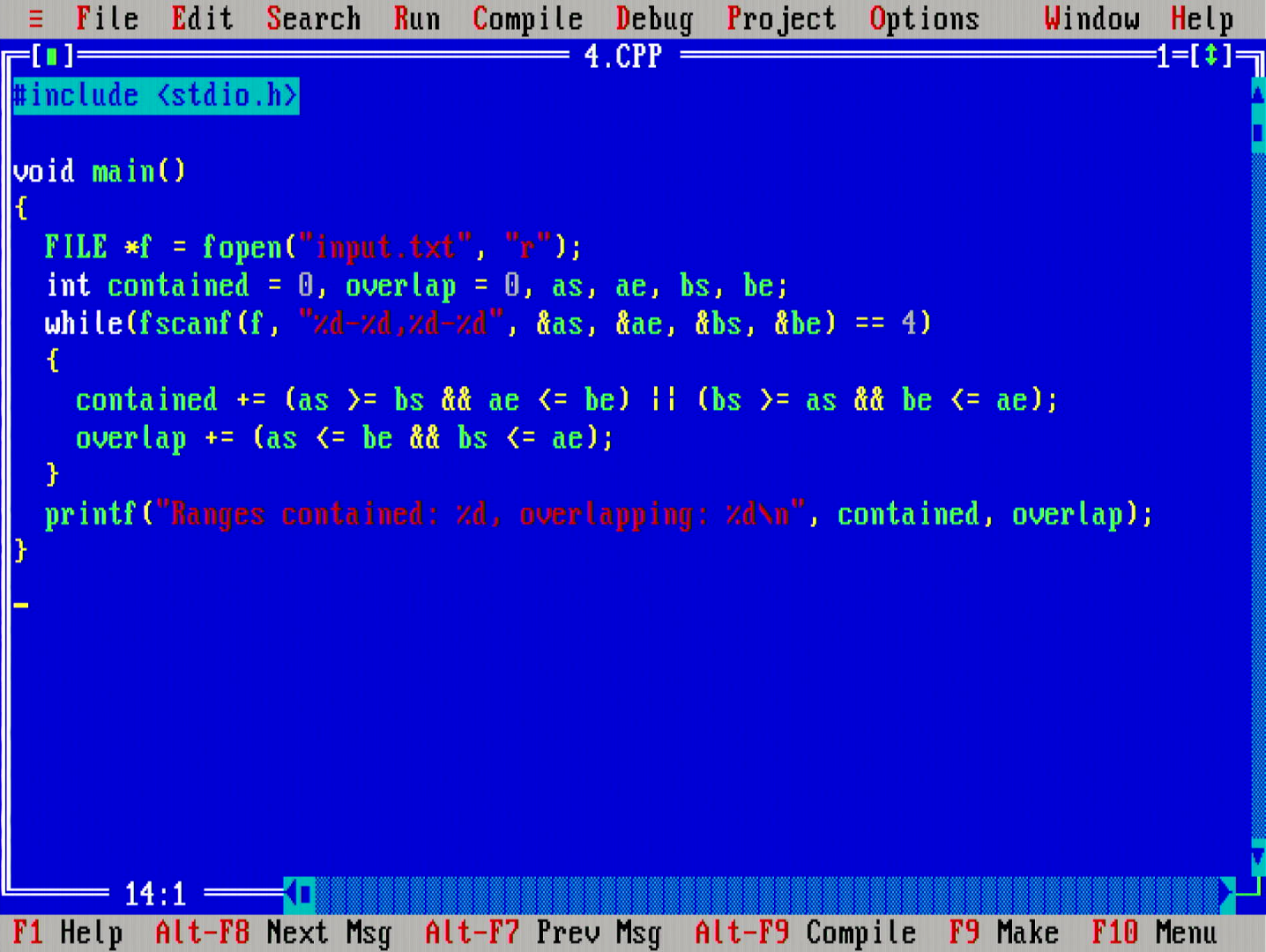 Cleaned up code looks like above.
Cleaned up code looks like above.
Twitch.tv video link. Solve time: 40 min 43 seconds. Runtime: 957 msecs.
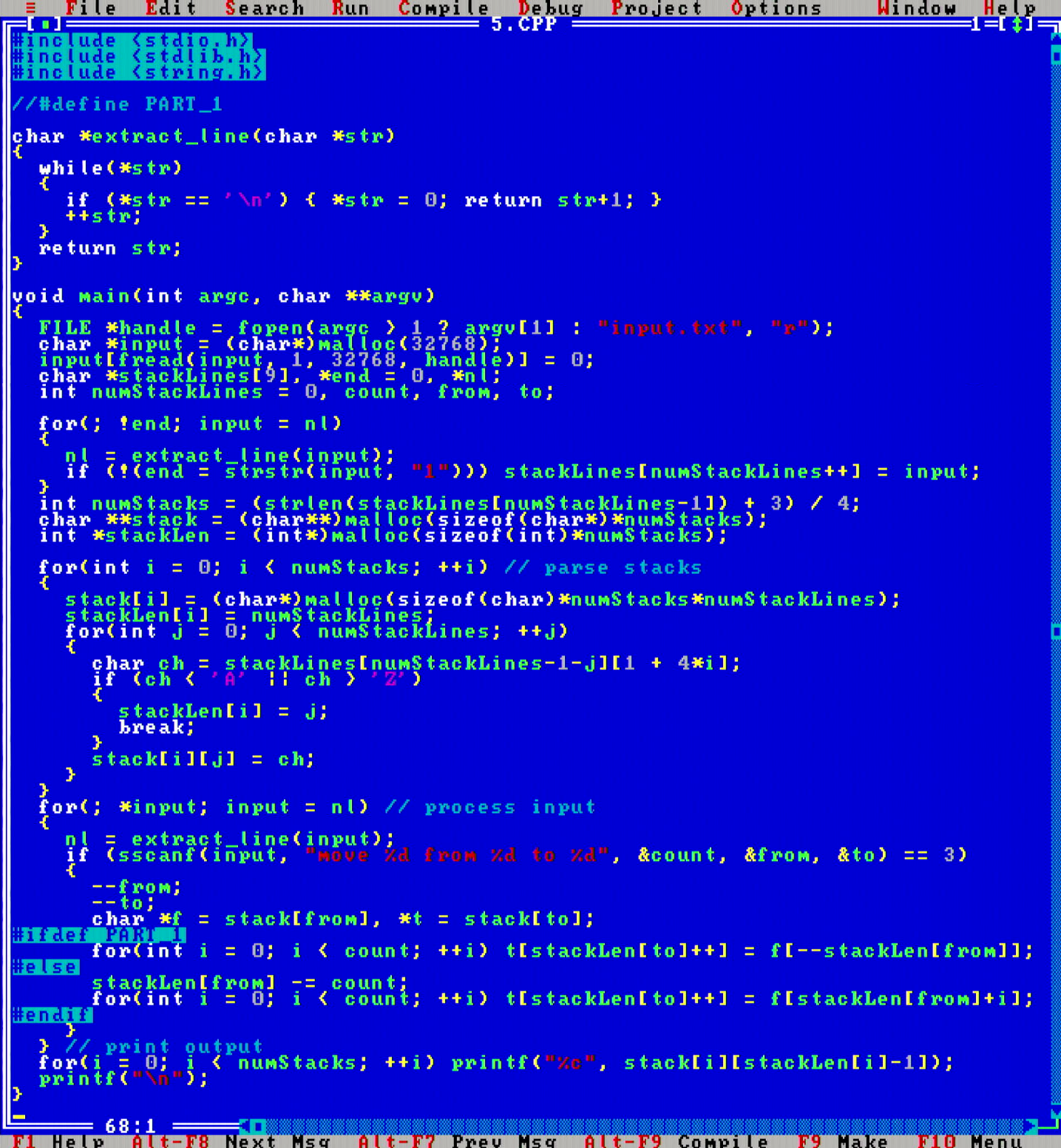
Day 5 makes me wonder if this is actually Input Parsing Christmas Calendar that I am doing. The algorithm was straightforward, but parsing the input, which needed transposing, was the hard part.
Today I decided to drop the previous batch function read_file_to_string(const char *filename) that would load the whole input file to string at once, since it looks like calling fscanf() to parse individual lines is decently fast as well. I have refactored the code from above days to drop the use of that function as well, to make the final solutions look shorter.

I also realized that if I place the work memory in DOS memory area B800:0000h, which is the screen text mode base address, then I can observe the computation that the computer is doing in real-time. Spiced this up by adding some delays and color highlights to create the above visualization.
Complexity linear. The distinction between parts 1 and 2 this day was a simple two line change.
Twitch.tv video link. Solve time: 57 min 2 seconds. Runtime: part 1: 822 msecs, part 2: 833 msecs.
This day is my favorite so far. This is because there are two interesting algorithmical ideas at play here. I feel good about the code I wrote for both parts for the 386.
The problem statement is: given a string, find the first occurrence of a substring of given fixed length k in that string, where each of the characters in that substring are distinct.
The first idea is to implement a search that avoids repeated comparisons. This is achieved by writing a variable length index increment in the inner body of the loop. Part 1 shows how this would work.
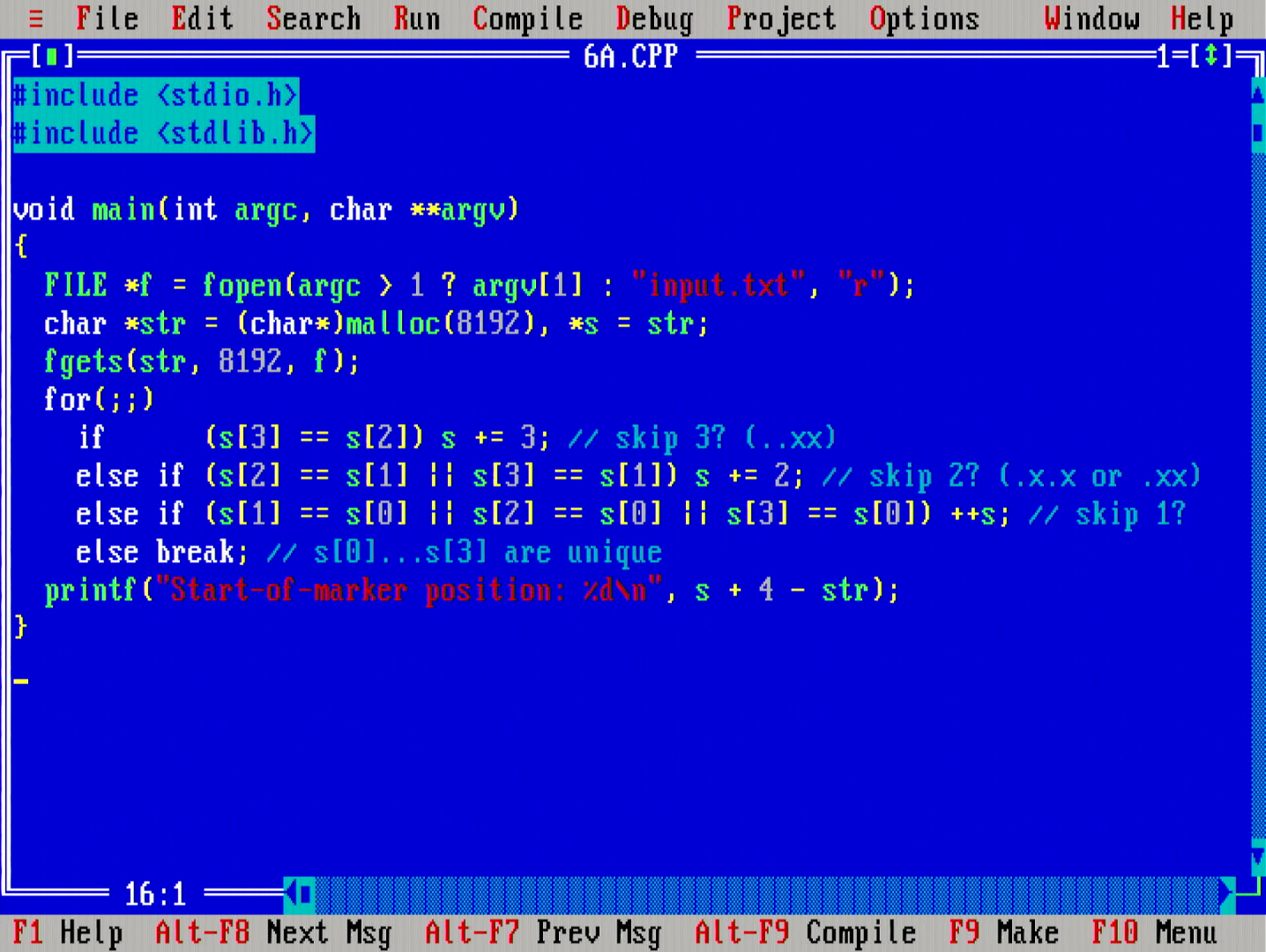
In the first part, we have k==4, a small constant, so we can compare the indices manually for a nice tight loop.
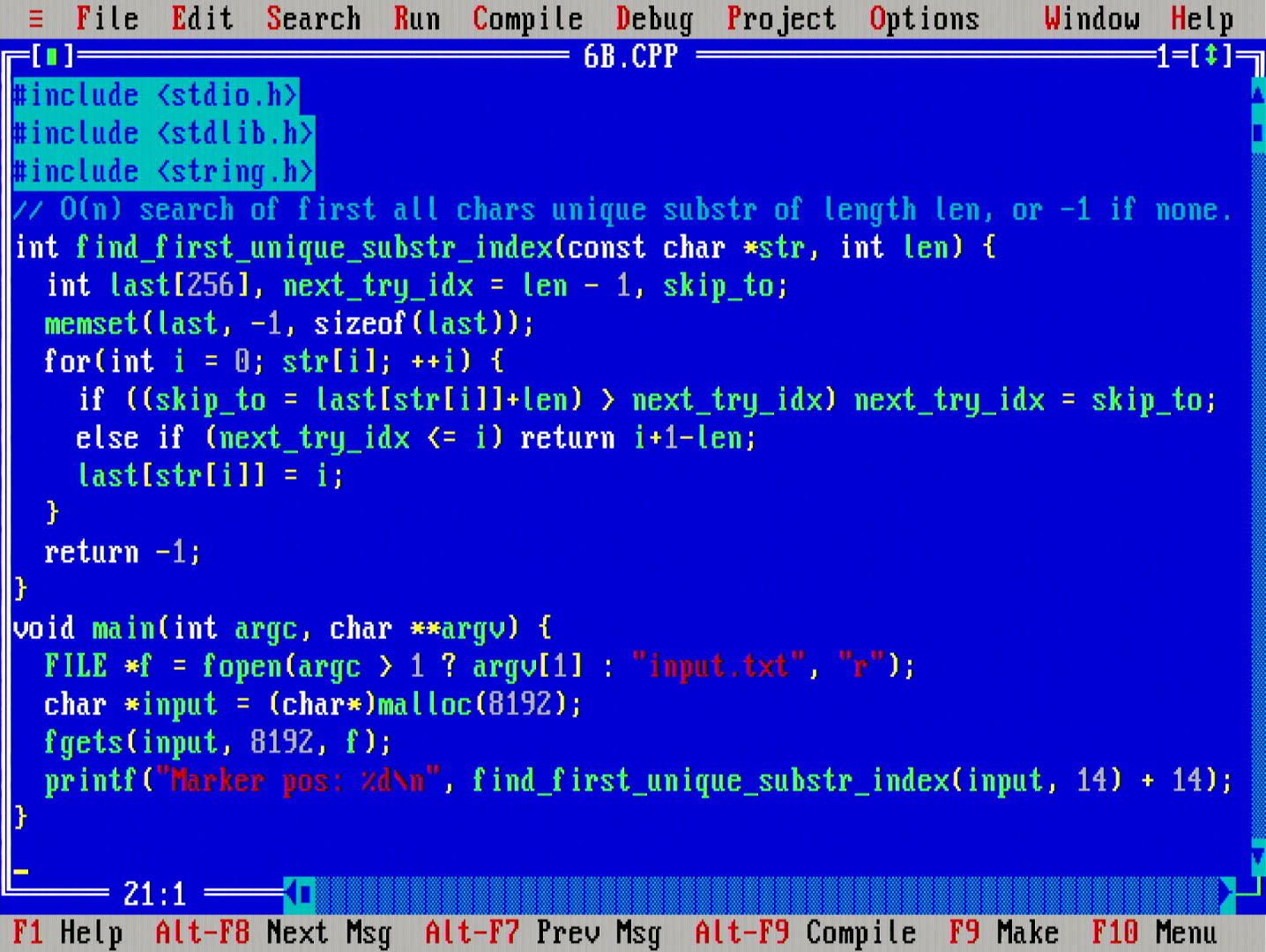
In the second part, we have k==14, so handwriting the index comparisons is no longer feasible. I came up with the above type of comparison algorithm. It has a really nice and tight inner loop with two comparisons, one addition, a couple of memory loads and one memory store. Runtime complexity is Θ(n+|A|) time and Θ(|A|) space, where A is the alphabet of the characters.
Twitch.tv video link. Solve time: 1 hour 11 min 6 seconds. Runtime: part 1: 130 msecs, part 2: 172 msecs.
On the seventh day of Christmas, the elves had filled the hard drive of their mystical gadget device with, uh, whatever they would fill their hard drives with, and the task was to delete the least of it to free enough space for an update.
I have implemented filesystems in C before, so it was natural to go with an inode tree structure to solve this.
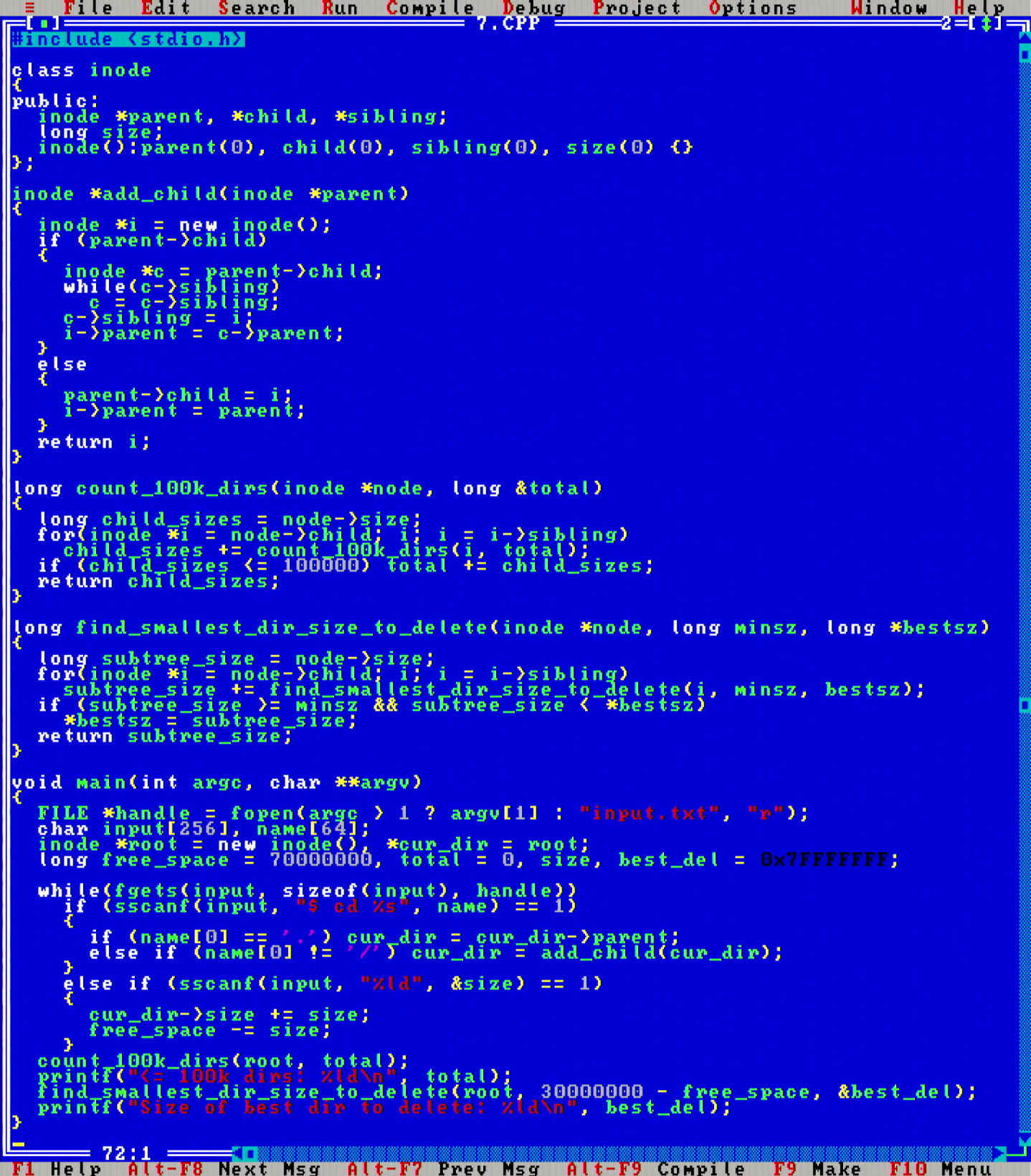
Not a challenge for the MikroMikko, memory usage was low and runtime were really fast.
Twitch.tv video link. Solve time: 1 hour 27 min 56 seconds. Runtime: 732 msecs.
At this point it seems that we have completely forgotten the mission, wasn't that to feed the reindeer? Now we're scouting locations for treetop tree houses, seems like someone's repurposing the elf labor for their own gain?
The problem today however is one of the more interesting ones. In the first part the task is to count the number of visible trees in a 2D grid.
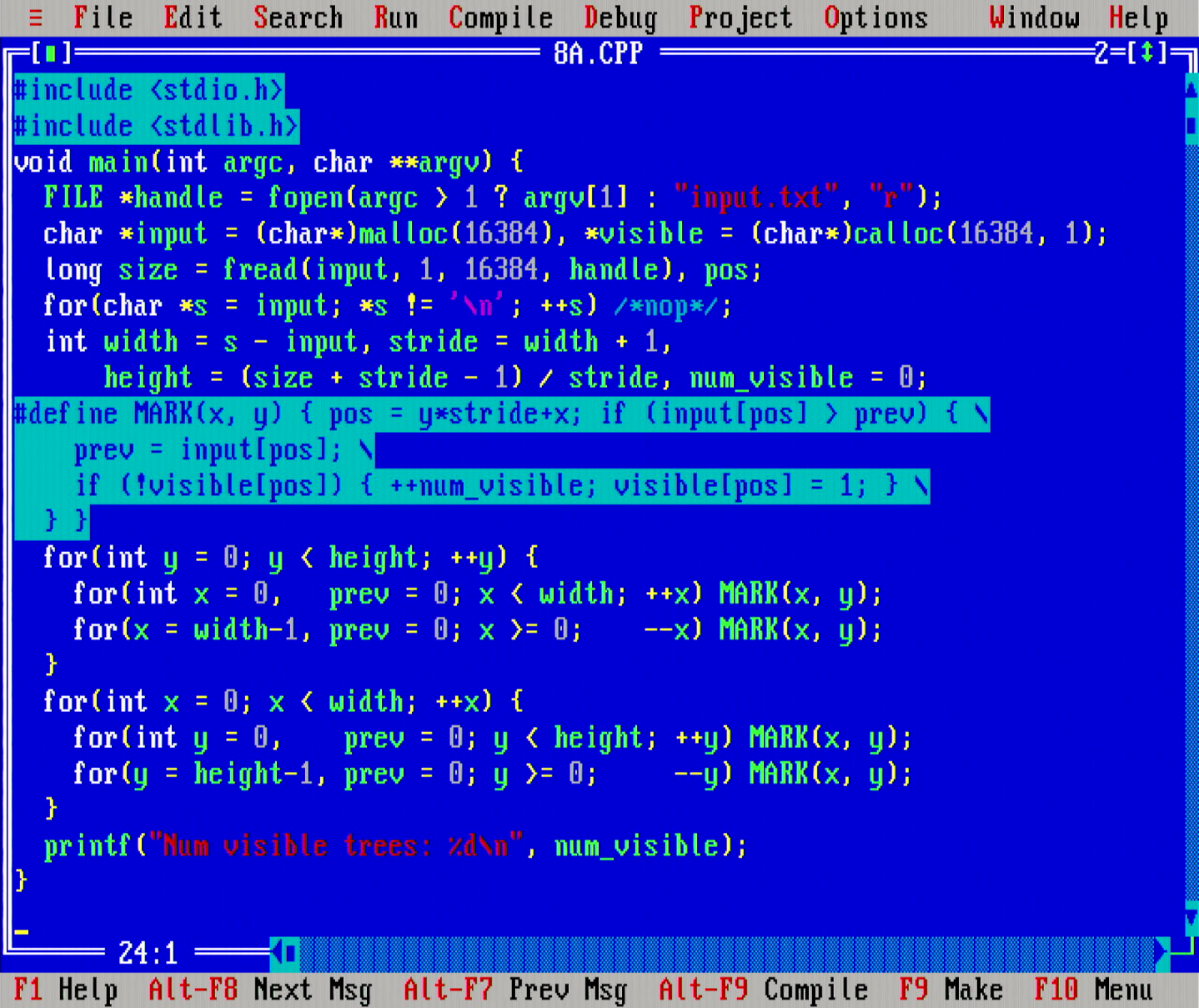
The problem can be solved by scanning inwards from every edge point on the map and marking the visible trees. Θ(xy) time and Θ(xy) space, where x is the width and y the height of trees in the forest.
Btw, can you observe something really odd about the for loops that call out to the MARK(x, y) function the above code? Only the first for loop in both inner loops define the int x = 0 (and int y = 0 farther down) variable, whereas the second for loop after that use x = width=1 (respectively y = height-1) without defining the variable, how does that parse?!
What is happening here is a feature of old C language syntax before the C language was standardized! In pre-standard C, the visibility of variables defined in the initialization block of a for statement extends outside the loop, not just inside it.
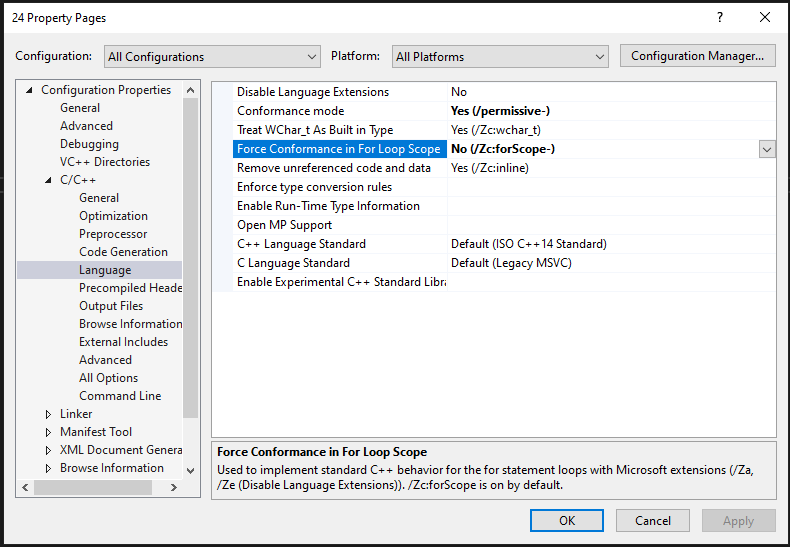
Remarkably, Visual Studio 2022 still supports this old syntax via its /Zc:forScope- compiler flag. However, the way they word the documentation for that flag does make it read as if this syntax was a Microsoft-defined extension, which it definitely isn't! Also, of course there are people calling Microsoft out for having a "buggy" Visual Studio compiler implementation, ugh.
TODO add dual nested for loop example
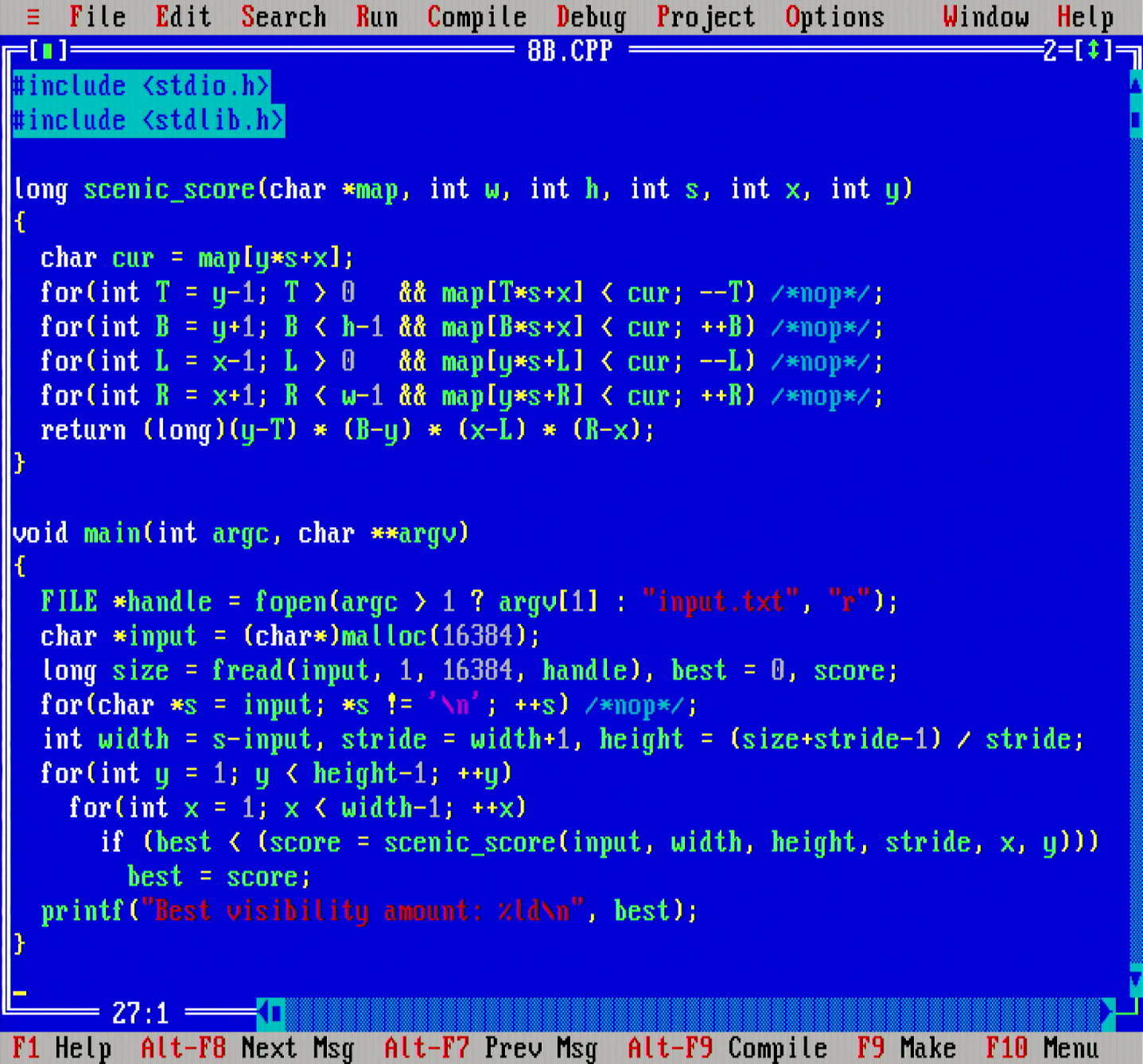
The second problem is an interesting variation that prompted some debate on its performance analysis. The challenge was to find the one tree in the forest that can see most trees (by using a special kind of metric to examine the "scenic" value of a tree)
My code checks every tree in the forest, and then for each tree, checks in all the four cardinal directions to count the trees each can see. Superficially it seems that this would result in a Θ((xy)²) runtime or at least a Θ((xy)*max(x,y)) runtime, but closer analysis suggests that this should not be the case, and actually the above algorithm runs in Θ(xy) time. See this Reddit thread for the amortized analysis to arrive to this conclusion.
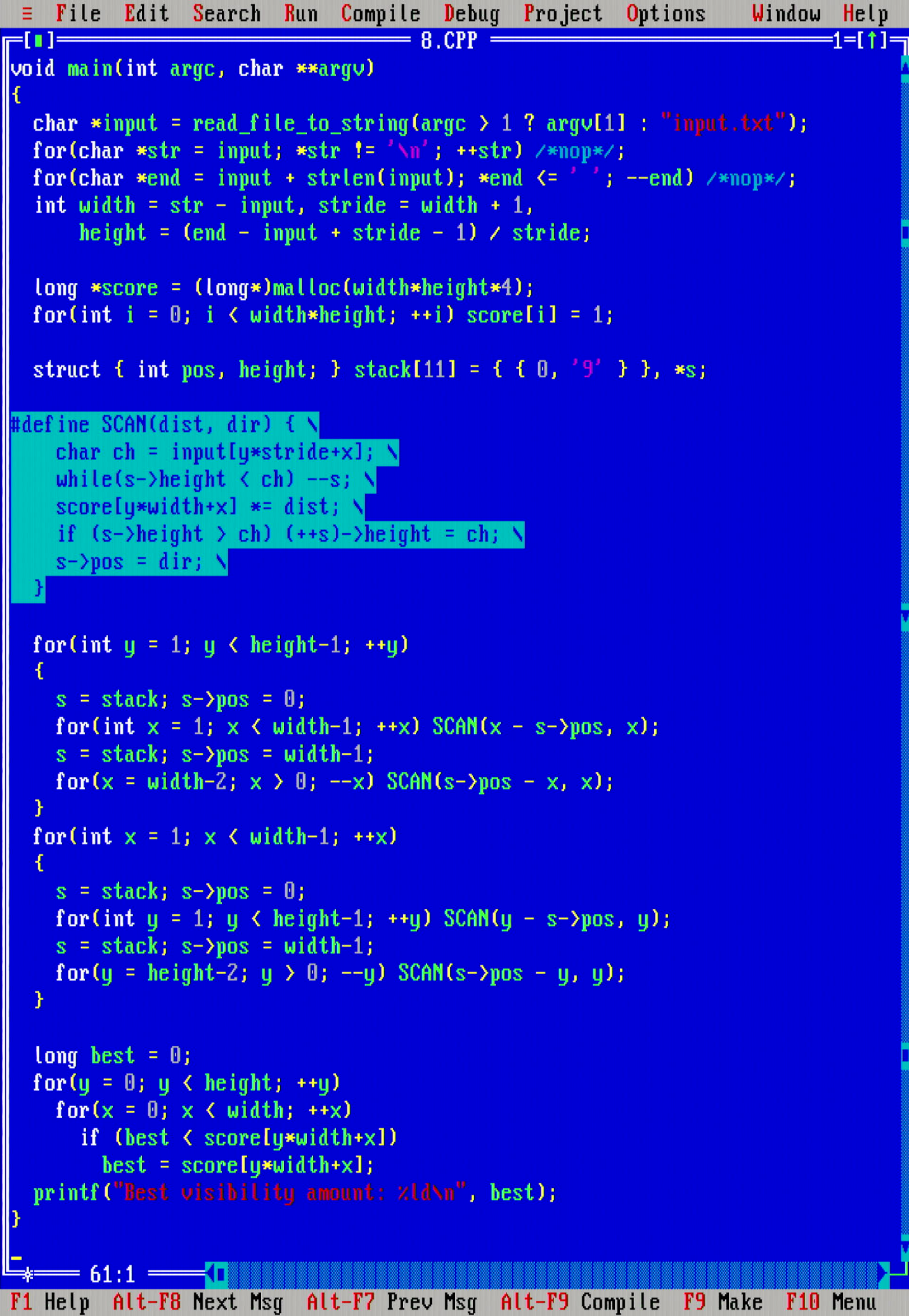
I did also implement the monotone stack variant of the code (which is easier to analyse to run in Θ(xy) time), and it did perform about the same.
The input map is 99x99 characters in size. This still fits easily in MikroMikko's memory, even when utilizing a near data+code memory model.
Twitch.tv video link. Solve time: 1 hour 3 min 2 seconds. Runtime: part 1: 623 msecs, part 2: 1683 msecs.
One the ninth day, we are crossing a bridge with the elves, but alas, it breaks, so we are simulating how a 2D ascii rope chain would follow a head node. In the first part, the task was to simulate only a two-part head&tail rope, but in the second part, the task was to simulate a 10-segment long rope.
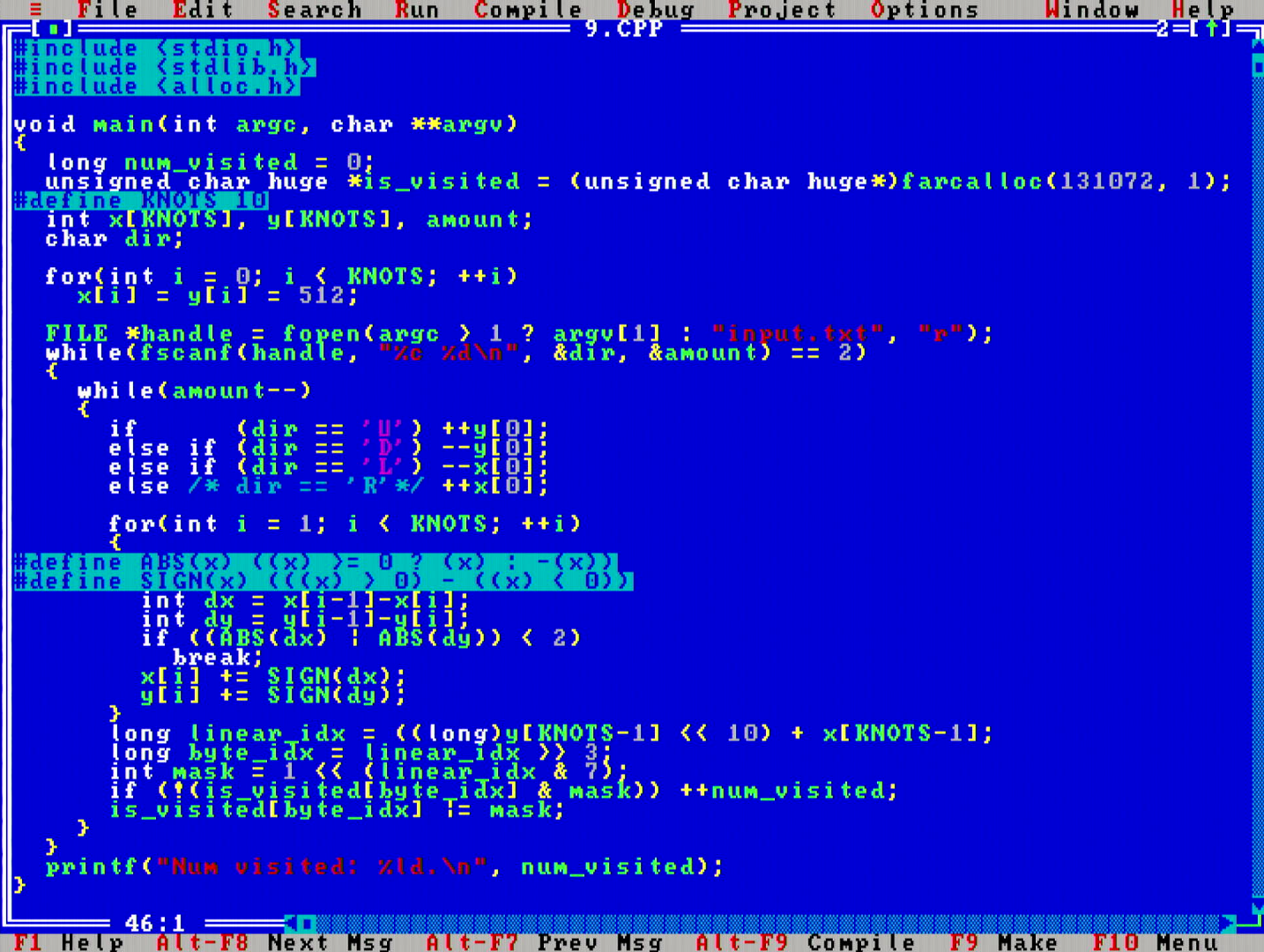
This is the first day where I have to resort to using huge memory pointer allocations. What are those you ask? Well, in the original IBM XT PC with Intel 8088 CPU, the memory address space was defined to be 20-bits wide, to be able to address 220 bytes = 1048576 distinct memory addresses.
However, the 8088 CPU itself did not have any registers that would be 20-bits long, but they were only 16-bits wide (i.e. 8088 was a 16-bit architecture). A single 16 bit register can address only 216 = 65536 distinct memory addresses.
So in order to access the whole 1048576 bytes long address space, one would need to use two 16-bit registers (well, one 16-bit register, and a 8-bit part of another register to hold the extra 4 bits). This would be quite awkward, so an "optimization" was devised based on the following observation: in any program, a lot of pointers typically will point to memory areas that are located near to each other. So in the context of operating on those addresses, the upper 4 bits would not likely change, so effectively only 16 bits would be enough to distinguish between addresses, and the upper 4 bits could be stored "globally" somewhere for all the pointers. The grand idea was to add some registers, called Segment Registers, to provide this common global context.
This way, in a C program, one could utilize so-called near pointers, which would be pointers that were understood in the context (or in the segment) of the currently set Segment Registers. A near pointer would be able to address at most 64KB of memory, but that memory is shared across all other near pointers in a program. Near pointers are 16 bits in size, for super fast and compact operation.
If the application needs more than 64KB of data, there are then far pointers, which are 32 bits in size, and can specify a full address. I.e. a far pointer stores the segment information of that data within it.
To complicate this programming model even a bit further, there was another observation made that would lead to an optimization: when a pointer points to an array, then during iteration of that array, the compiler commonly needs to calculate byte offsets to the individual elements in that array. If the array is <= 64KB in size, then the compiler could implement those offset calculations correctly using just a single 16-bit offset register. However if the data array is > 64KB in size, then the compiler should utilize two registers for the offset. These two scenarios were distinguished between because utilizing 2x16-bit registers to simulate a 32-bit register would be considerably slower than utilizing a single 16-bit register. Since the compiler would not be able to automatically deduce whether it could use 16-bit offsets, a manual aid was added: pointers that point to an array that is larger than 64KB were named huge pointers.
So, finally, we get the following pointer model table for the Intel "real mode" data access:
| Name | Meaning |
| int near * | 16-bit pointer, located in the same shared segment as all other near pointers. |
| int far * | 32-bit pointer to <= 64KB of data, so indexed with a 16-bit offset during iteration. |
| int huge * | 32-bit pointer to > 64KB of data, so indexed with a 32-bit offset during iteration. |
| int * | Depending on the build settings, this will either mean a near, far or a huge pointer. |
Wow, what a confusing mess. By now you can really imagine how much programmers must have loved when CPUs got faster and memory capacities grew so that always utilizing 32-bit pointers no longer carried a performance penalty, and none of this model was needed. (also, imagine in today's context if we had the same: say implementing a 64-bit program, but had to sometimes shrink pointers to 32-bits since 64-bit pointers were too big so they slowed down the program? Yeah, glad we don't have that kind of bs anymore. Wait what?)
Anyways, back to day 9 code. Now you can understand the unsigned char huge * pointer in the beginning of the program. It is a buffer of 131072 bytes in size, so since it is >= 64KB, it requires using a huge pointer. This array can fit a 2D map of 1024*1024 individual bits in size, and is used to detect all the 2D positions that the tail of the rope would travel. Runs still quite fast on the 16MHz CPU.
Make note of the break; statement in the innermost loop. That is a nice early out check to stop simulating rope segments when part of the tail is not moving. This speeds up the simulation considerably.
Twitch.tv video link. Solve time: 1 hour 54 min 16 seconds. Runtime: part 2: 2885 msecs.
Here we needed to "race the beam" of a simulated CRT device to decode a message.

One of the nicer parts of this problem is that it lends itself well for visualizing, so I reused the idea from day 5 to do the computation in graphics adapter's text mode RAM.
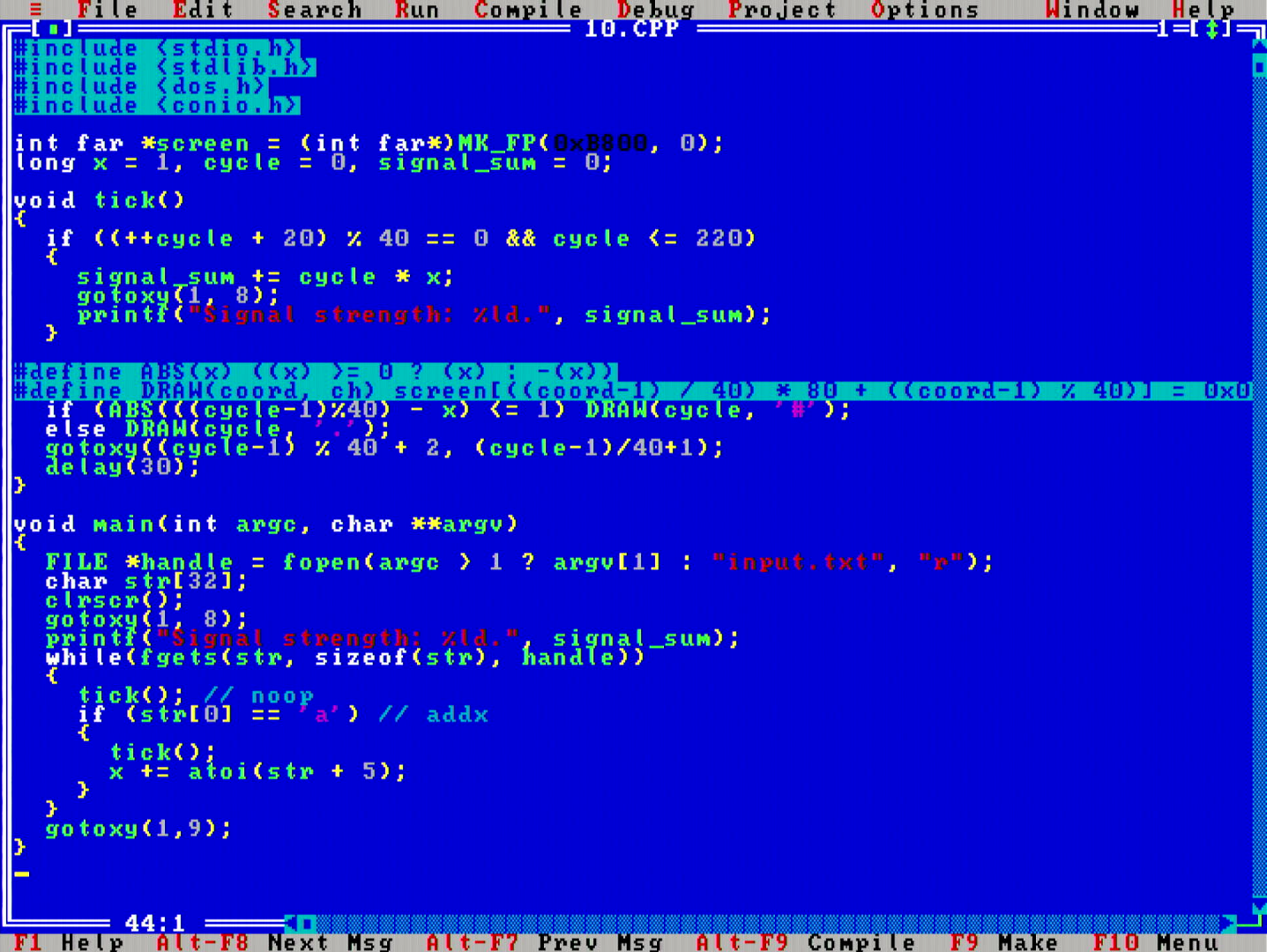
Twitch.tv video link. Solve time: 58 min 14 seconds. Runtime: part 2: 75 msecs.
Monkeys are throwing stuff around and computing values larger than 2210000. I don't have BigInt code for my 386, but fortunately for me, this problem would not even be solvable by using a BigInt even on modern computers.
I did not feel like playing Input Parsing Christmas Calendar this time, so I hardcoded the problem input to my program. This proved to be a great time saver.
However, Borland Turbo C++ 3.0 does not support 32bit*32bit=64bit multiplication nor 64-bit remainder operations. This provided me with an extra challenge to emulate those operations. Curiously, Borland Turbo C++ 3.0 does have the unsigned long long data type, but that is also only 32-bit, and not 64-bit. Oh dear!
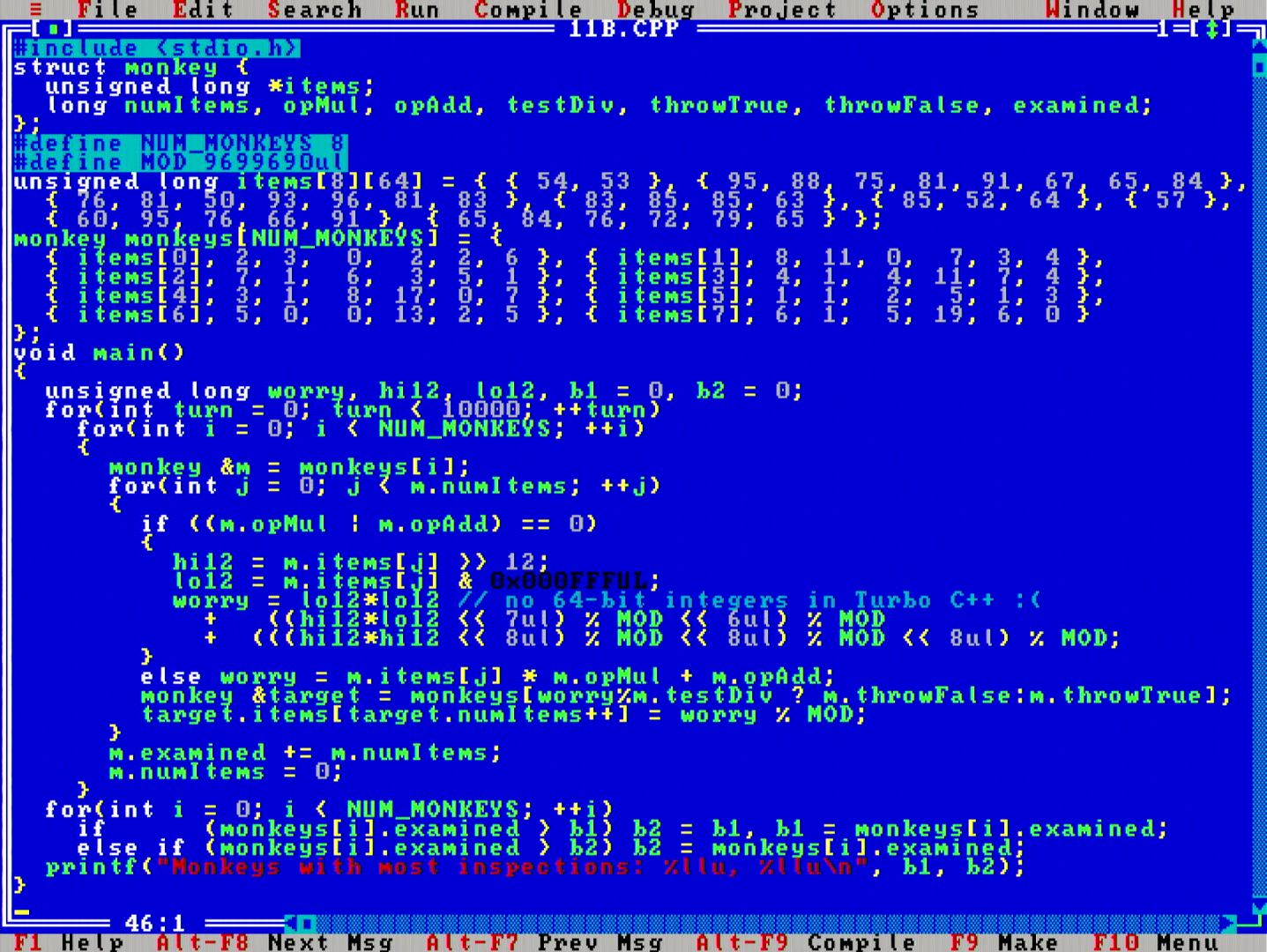
It took me quite a while to write such emulation, looks like my multiply-in-parts skills from the fixed floating point era were quite rusty. The first version was a big hack, but I was able to clean up the code afterwards, shown above, which looks much better than the ad hoc horror I attempted first. I also realized that I actually did not need a >32-bit remainder operator, since the modulus did keep in check.
Twitch.tv video link. Solve time: 2 hour 9 min 9 seconds. Runtime: part 2: 4 minutes 14 seconds.
Today's puzzle was asking how to climb up a hill from start to an end. I did not implement any fancy A* here, but instead solved it with a naive Breadth First Search loop from Start to End.
Being naive helped out for the second part, where the task was to find the shortest path from the End to any position at height 'A' - here A* would have gotten in the way, as BFS search is needed anyway. Sometimes being lazy pays off!
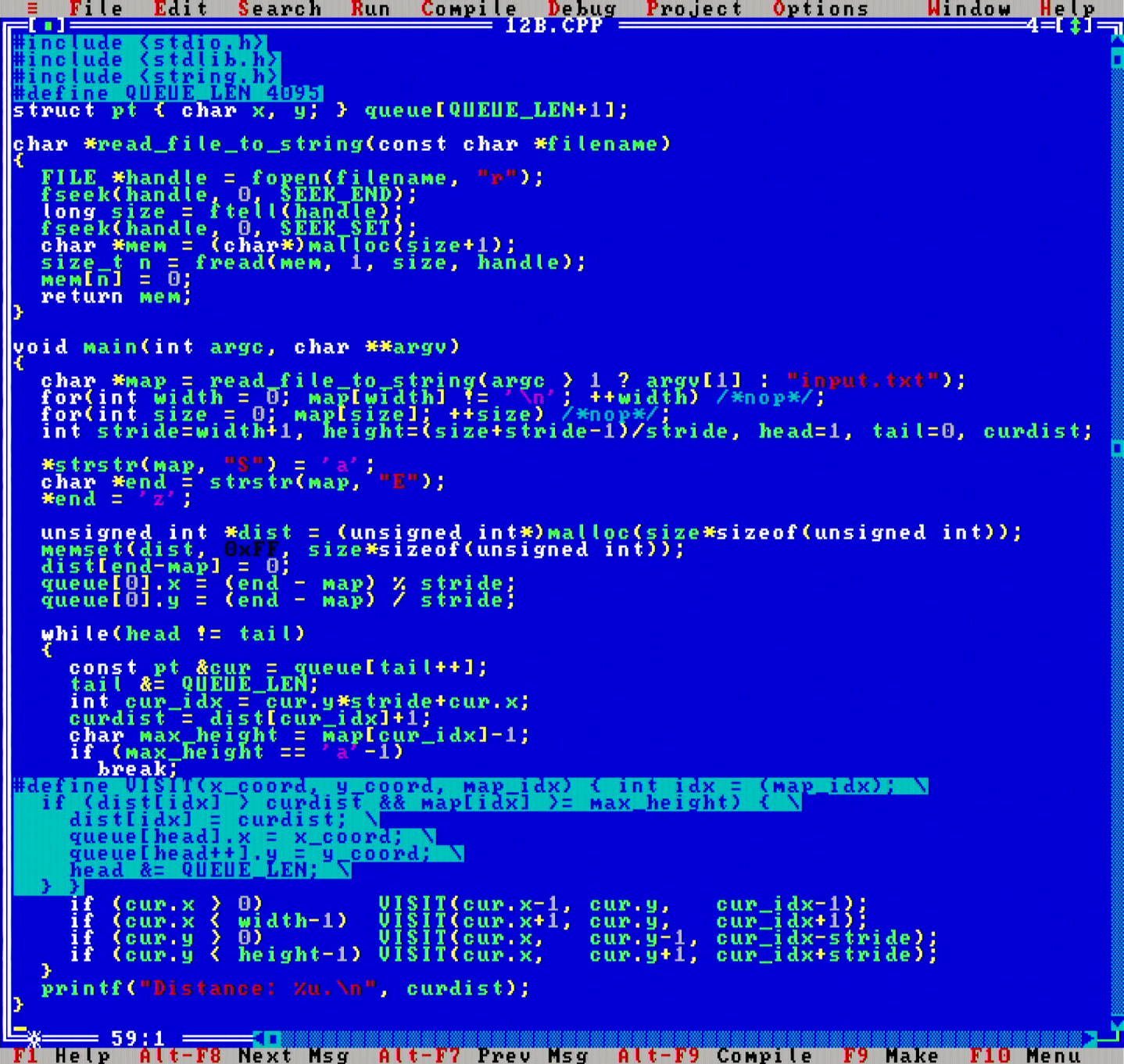
Final code for part 2. All a breeze for a powerful computer like MikroMikko.
Twitch.tv video link. Solve time: 1 hour 2 min 8 seconds. Runtime: part 2: 340 msecs.
This day was another Input Parsing Christmas Calendar day, however this time it did not feel like an obstacle, but rather, this puzzle was well crafted to set an expectation that "input parsing is part of the problem" as opposed to having a feeling of "input parsing is an obstacle you have to clear before you can get to the actual problem".
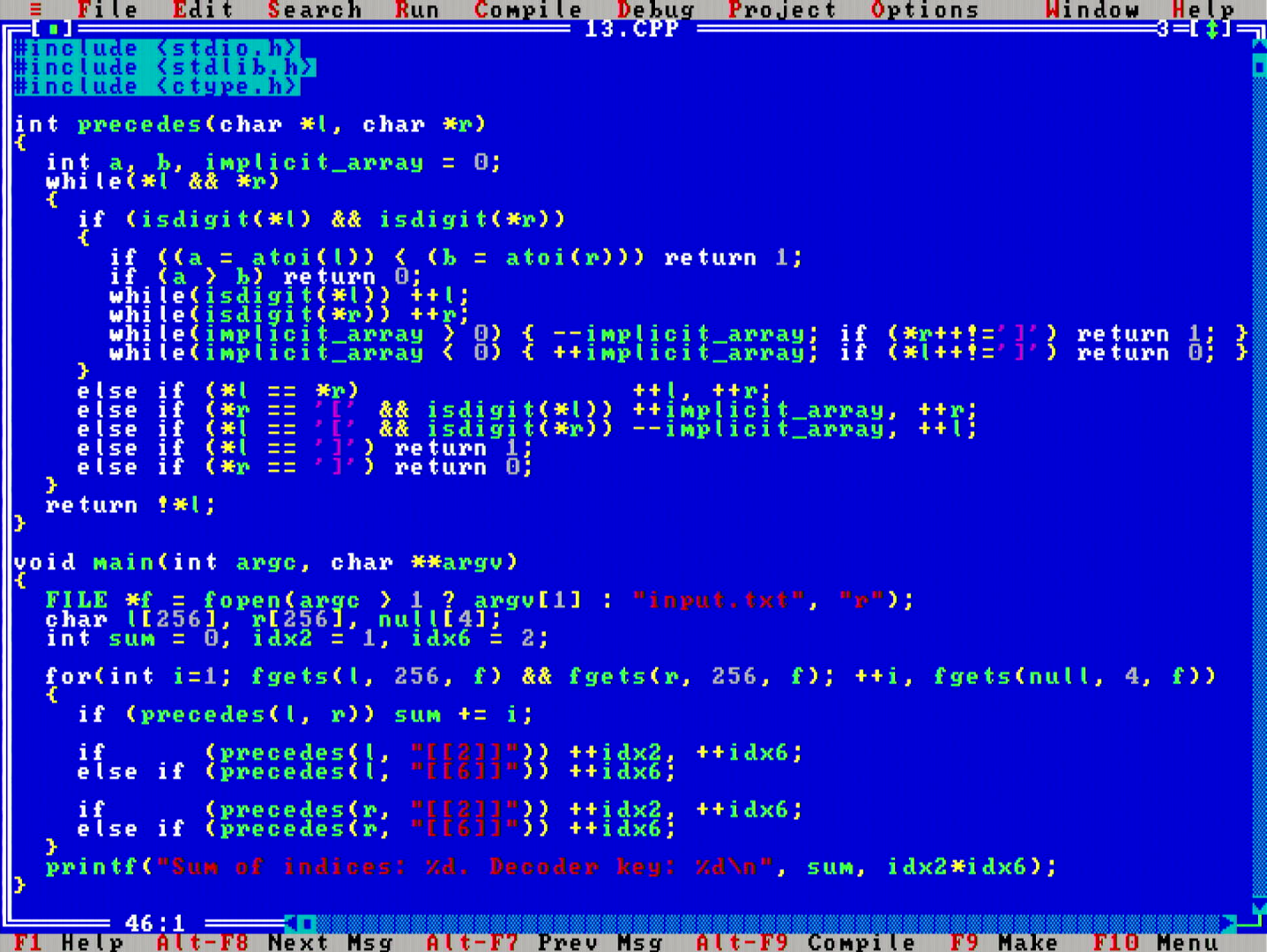
No recursive descent or lookahead parsers here, but instead, I chose to do a single pass compare function that compares the two objects directly as strings. Oh do I love the compactness! Θ(n) time and Θ(1) space.
Twitch.tv video link. Solve time: 1 hour 43 min 4 seconds. Runtime: 682 msecs.
Hey! This is exactly like a DOS snowfall simulation that I wrote when I was a kid. I don't know exactly when that would have been, but I have a saved screen grab from 2003.

I like the story setting in this problem: we are locked in a cave complex where sand is falling in, and we need to simulate piles of sand falling down.

DOS mode 12h is a 640x480x16 colors graphics mode: the top-of-the-line best resolution graphics mode that standard VGA was able to offer, although not many games used it due to the restricted number of colors (compared to the legendary mode 13h 320x200 at 256 colors). Nevertheless, mode 12h video mode enables a nice way to visualize today's problem, so I pointed the PC's work RAM to A000:0000h, and I could see in real-time how the simulation was going.
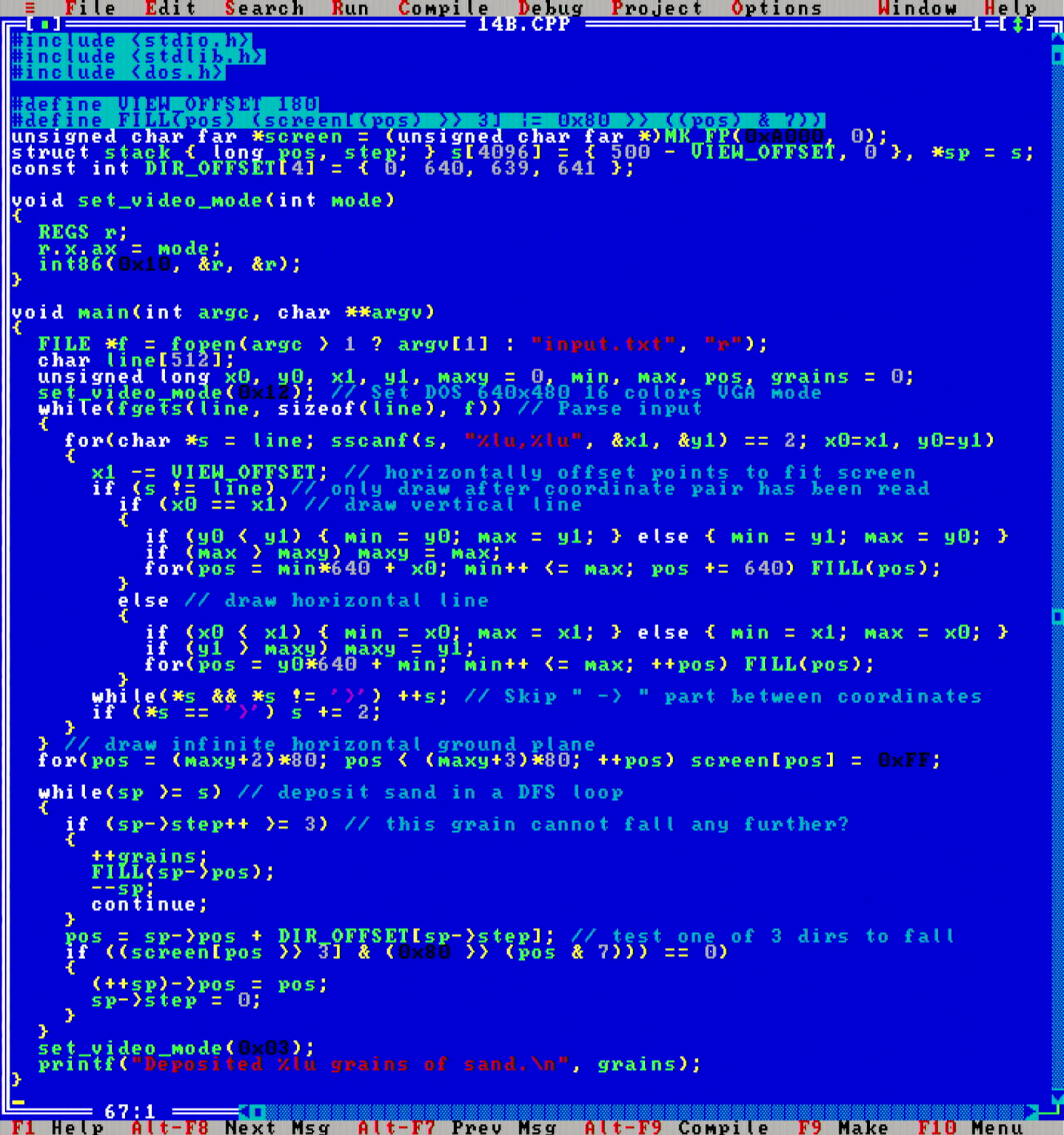
See how little code we need to implement this visualization? The function set_video_mode(int mode) activates the desired video mode, and a call to MK_FP(0xA000, 0); obtains a far pointer on the screen buffer. Neat!
This day gives a glimpse to how interfacing with different hardware peripherals worked in MS-DOS: one invokes hardware or software interrupts to access them (here via the int86() function). This was crude, but extremely fast and effective. Unfortunately it did have many shortcomings (weakly compatible with the invention of multiprocessing, hard to guard, no good driver abstraction, to name a few), but I have to admit, it still is a really nice way to operate - just that it does bring more a feeling of embedded programming to it.
As an optimization, I implemented a stack-based search loop (a DFS search) to improve the runtime from Θ(n*y), where n is the number of sand grains until the screen is full, and y is the height of the screen, to just Θ(n).
Twitch.tv video link. Solve time: 1 hour 40 min 43 seconds. Runtime: part 2: 4982 msecs.
On day 15 we have a sensors and beacons problem. There are multiple sensors on a 2D map, which all report the coordinates of only the nearest beacon they can see. The task is to find which 2D coordinate on the map is not covered by any of the sensors.
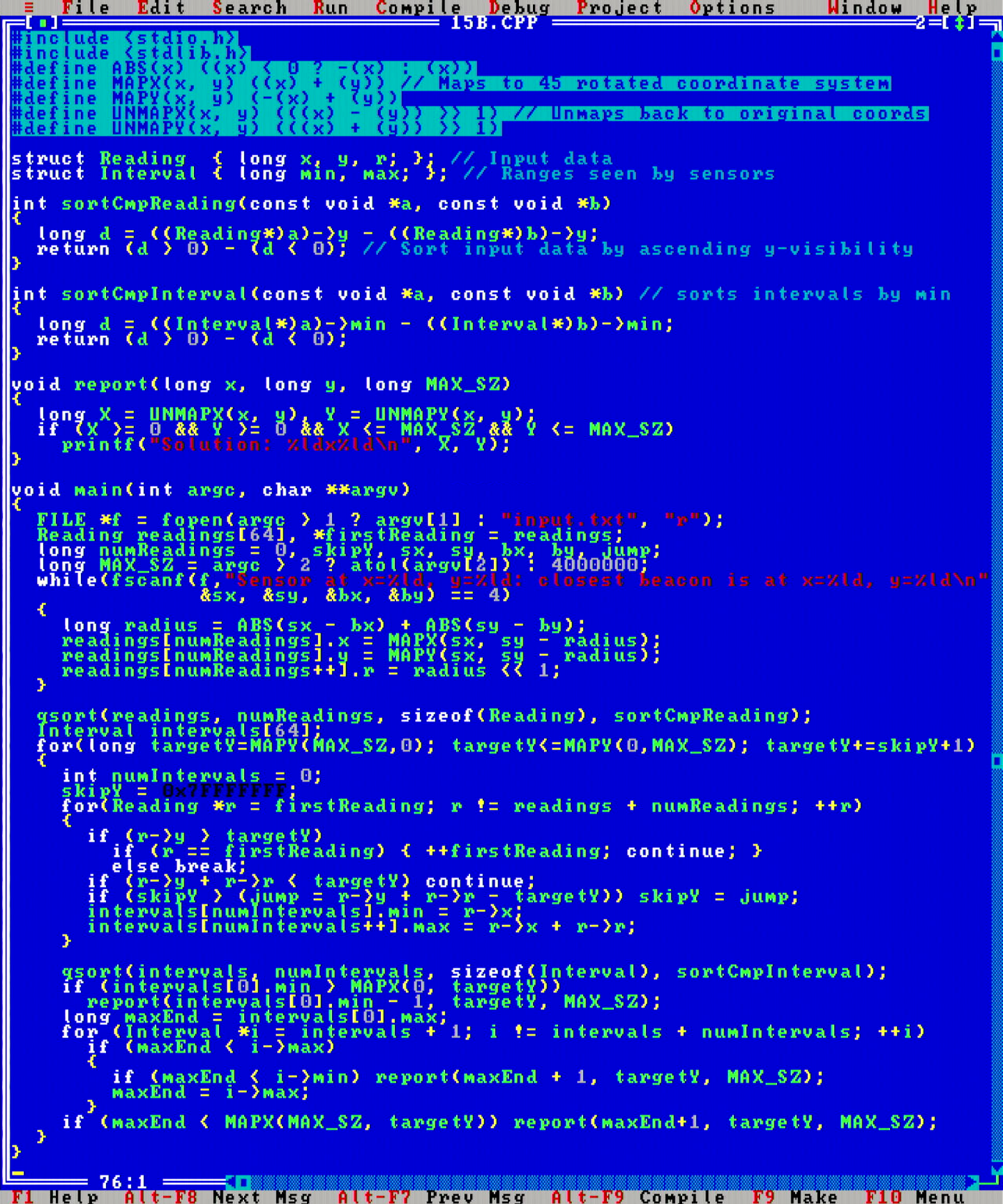
My approach was to rotate the coordinate system by 45°, and then implement a sort-and-sweep algorithm to observe which scanline on the grid was not covered. This runs amazingly fast, I'd believe in Θ(n*√n*logn) time (assuming uniform sensor distribution) and Θ(n) space, where n is the number of sensors on the map.
Twitch.tv video link. Solve time: 1 hour 47 min 30 seconds. Runtime: 112 msecs.
This is the first day where I really struggled with running out of memory. The problem on day 16 calls for using memoization or dynamic programming approach, where the problem is divided up into subproblems, and the intermediate results of those subproblems are cached.
This day I also realized that something that I struggled with is the productivity of MikroMikko for exploratory programming. In order to understand the problem space better, I needed to do some experiments, but the compilation speed and memory amount on this PC is not enough to enable that.
So what ended up happening today is that I did the needed experiments, and implemented the solution first on my Ryzen 5950X desktop PC, and then ported the solution over to run on MikroMikko. The Ryzen PC filled about 450 MB of RAM for the memoization cache to compute a solution. Wow, I certainly couldn't fit that onto the 386.

On MikroMikko there are two sticks of 1024KB of RAM each, although because Borland Turbo C++ 3.0 is a real mode compiler for the 8088/80286 era, and not a protected mode compiler like the later popular DJGPP+RHIDE combo would be, acquiring a) access to this full amount of memory b) quickly and c) for random access patterns like a memoization cache would need, is difficult.
To access the full 2MB of memory, I would need to use either XMS or EMS standards. I learned that XMS actually does not give direct access to the allocated memory, but one needs to utilize memory block copies to transfer the data between real memory and protected memory. There is a workaround to either utilize the assembly LOADALL instruction or to transition to unreal mode, but my understanding is that I would then have to use assembly code to access the data, which I thought was too large of an exercise for one day.
The EMS standard does allow allocating the full protected memory area, and then mapping a single full 64KB page of that memory at a time to real mode DOS application space. (or maybe even 128KB page frames might be possible? I am not 100% sure). Maybe EMS memory would be slightly better, since at least it would be zero-copy?
The good part about memoization caches is that they are just caches. You can actually use whatever amount of memory you want for such a cache, and when it gets full, you can overwrite/discard old parts of the cache using whatever eviction strategy you deem suitable. So that is what I did: I allocated up all the memory I have code to access to so far, about 600KB of base memory and 128KB of video RAM, and then used that as the memoization cache hash table, and put the MikroMikko to work.
Eventually the computation would finish, and with some optimizations it turned out to take only about 80 minutes of computation time. This MikroMikko is not branded "TT" (TehoTyöasema, or "power workstation") for nothing!
You can see in the above photo that there are two unpopulated SIMM slots that could expand to 4MB of RAM, and the obvious question is that could I compute the result faster if I added more RAM?
I did some simulations on the Ryzen PC where I'd use as much (or little) memoization cache on the Ryzen as I would have space to allocate in EMS memory if I had 4MB, and got an estimate that I could cut the runtime down to 2/5ths of the original run, so 2/5*80min ~ 32 minutes, assuming that the performance overhead of remapping EMS pages would be zero - which it certainly would not be. So I was not that keen to jump on implementing that version just yet. Maybe something to think for the future.
 I even leveraged 128 KB of the integrated VGA adapter's graphics memory (A0000h - BFFF0h) to use as cache memory. Thanks Paradise!
I even leveraged 128 KB of the integrated VGA adapter's graphics memory (A0000h - BFFF0h) to use as cache memory. Thanks Paradise!
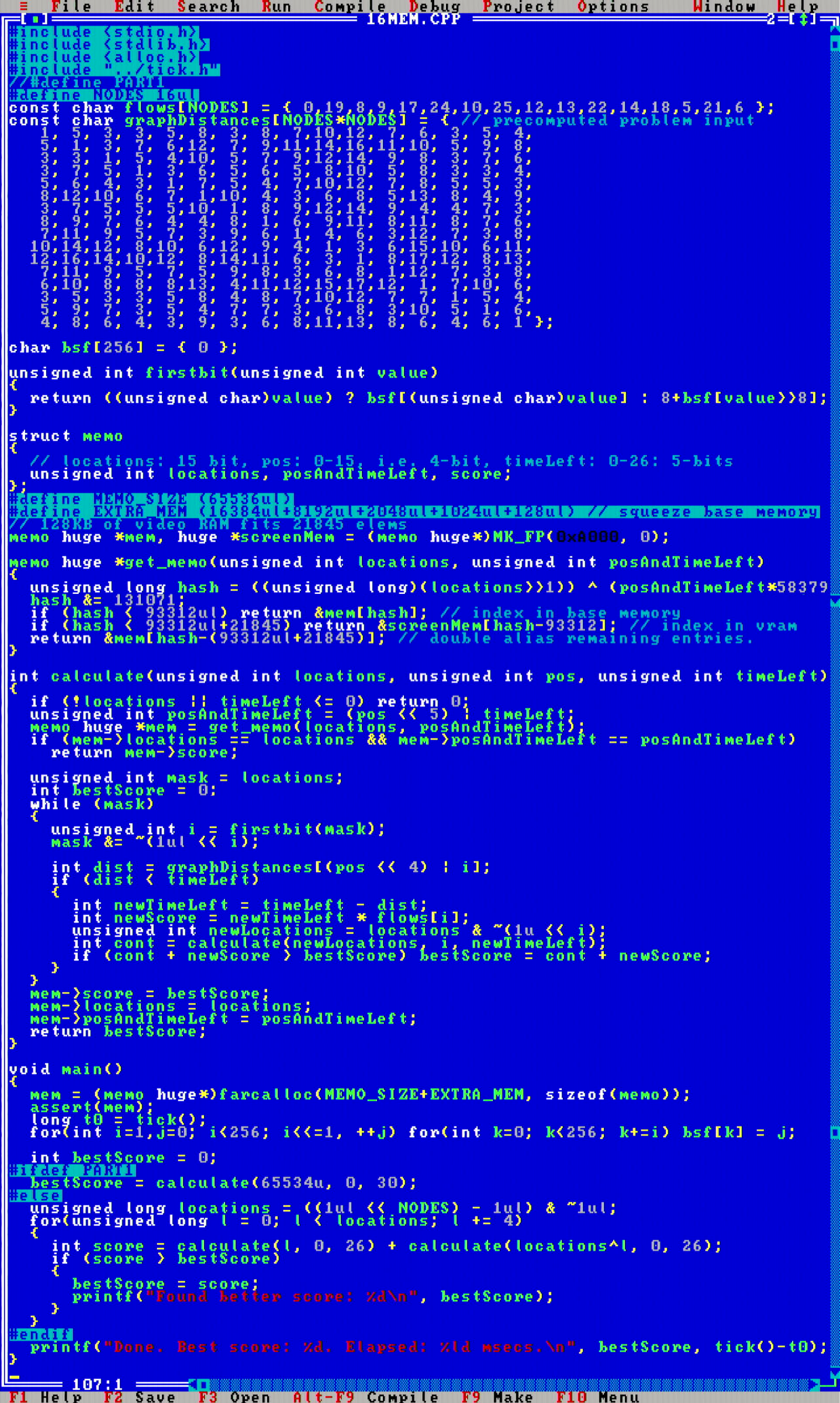
In this problem I also hardcoded the problem input, by first compacting the graph from useless zero-flow nodes. Memoization in final version looks a bit gnarly.
Twitch.tv video link. Solve time: 1 hour 3 min 3 seconds on video + maybe 4(?) hours offline. Runtime: part 1: 24.7 seconds, part 2: 80 minutes.
On the seventeenth we are playing Tetris on an astronomically long board. This puzzle relies on a trick of finding a cycle in the state space. At first I was going about it really diligently, looking to implement a full state cache of current_block × current_jet_flow × tetris_landscape, and detect when there would be a cycle. But then after poking the issue a bit by just observing periodicity of current_block × current_jet_flow, I realized that the height increments exhibited strong periodicity only after two cycles, so I just tried using that as the cycle length as an "opportunistic" guess, and it worked.
Today marked a second case of a productivity problem on MikroMikko, just like yesterday. Doing "exploratory" investigations on the 386 in a computing heavy scenario is quite inconvenient because of long compilation times, so I opted to do the exploration on the Ryzen, and again port the final solution code to be computed on MikroMikko.
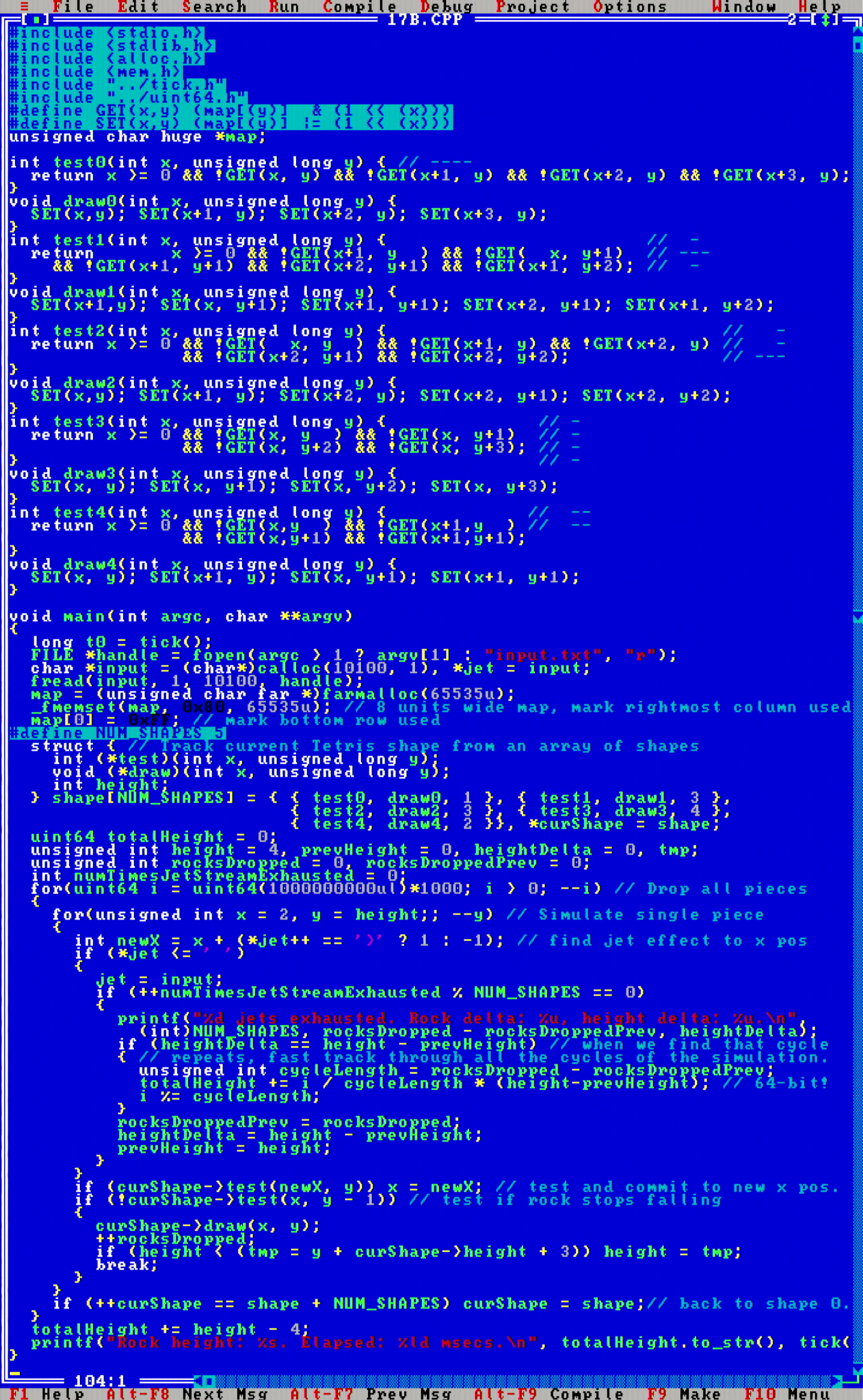
This code also showcases a pattern I found surprisingly commonly recurring during this challenge: one-bit 2D arrays. Compare to code on day 14. Since memory is so scarce, efficiently utilizing all available bits of memory is crucial. Each byte can hold eight bits, so let's make the best use out of them. The GET(x, y) and SET(x, y) pattern will also repeat on later days.
Finally, the arithmetic that is needed to compute the result requires 64-bit integers. I created a UINT64.H helper header to add a simple uint64 type that follows the modern standard uint64_t type. (This header was further needed on the puzzles from later days, so check down below for its final version)
Twitch.tv video links: part 1, part 2. Solve time: 2h 50 min 3 seconds on video plus maybe an hour offline. Runtime: part 2: 25.9 seconds.
After the two time consuming days 16 and 17, this day felt like a welcome pause. Nothing complex here, a Θ(n+xyz) runtime with a Θ(xyz) space, though fortunately the 3D map size was modestly small to not blow up the memory size.
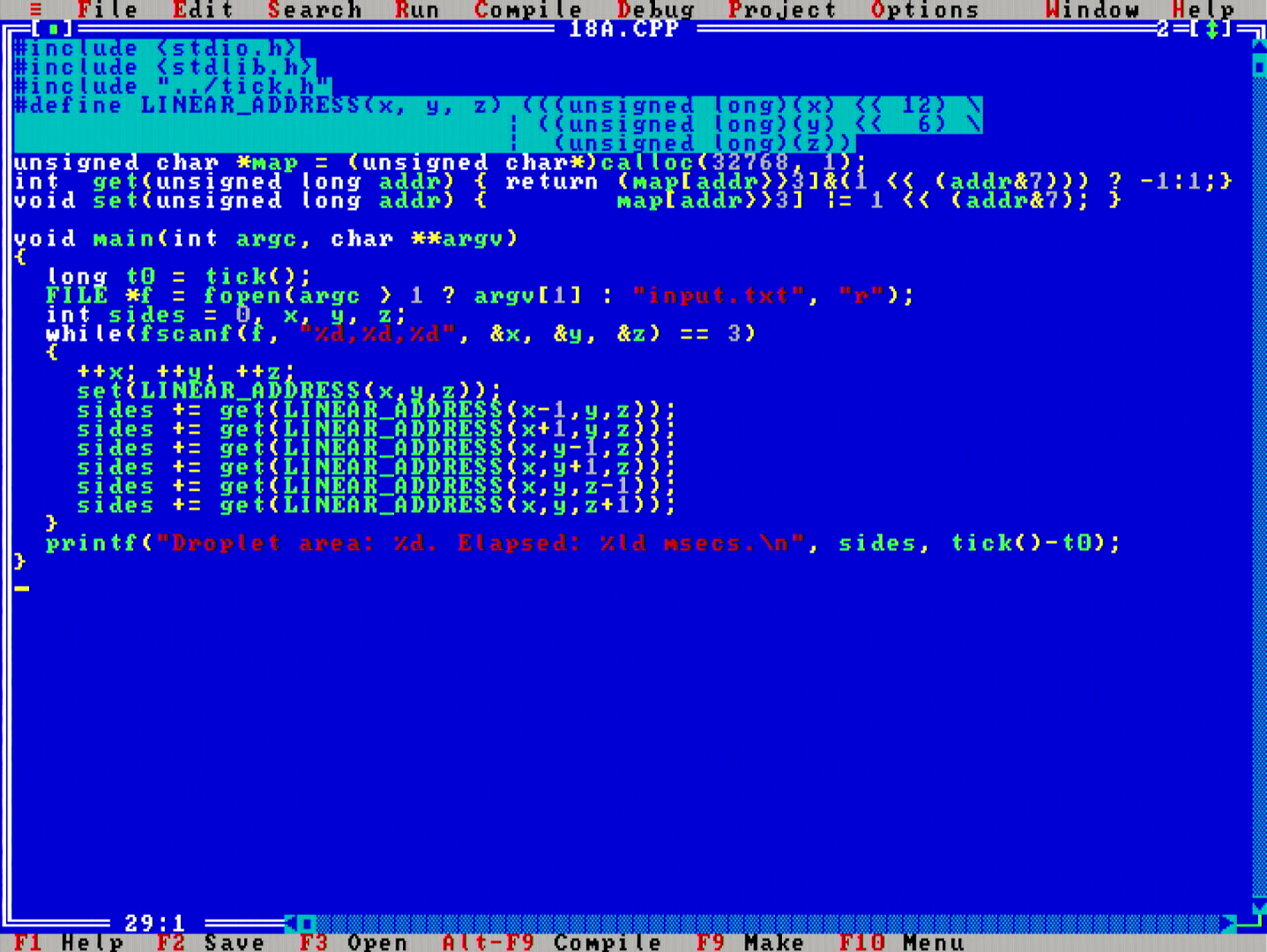
It felt really cute to realize that part 1 of today's problem admits this kind of an online one pass algorithm.
You may have noticed this code and the code from a couple of previous days to include a header named tick.h. On day 16 I had to get more serious about profiling code runtime speed. I was searching how to do high precision wallclock timing on DOS, and turns out that Microsoft did not provide any APIs for this with MS-DOS, and neither does Borland with their Turbo C++ compiler.
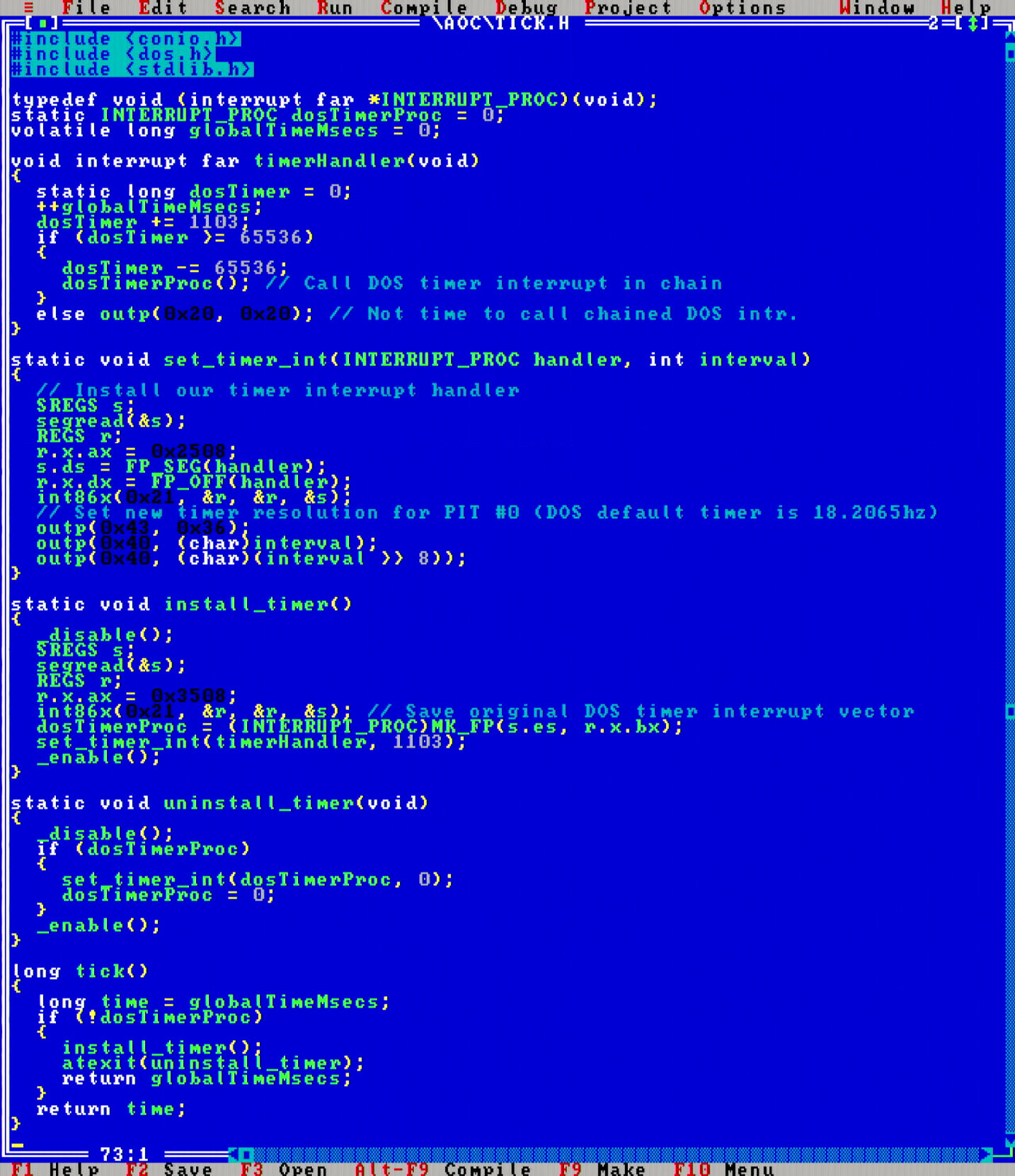
To achieve high precision timing, one must reconfigure one of the PC hardware PIT timer channels to increase its firing rate. I ended up writing the above utility code to achieve that.
One of the drawbacks with that code is that it is not assert()-friendly. If any assertions fail in my code, then atexit() handlers will not be run, and if there were any custom interrupt handlers installed, the PC is going to hard crash (since those handler functions are no longer resident in memory). Maybe to fix this issue, I would have to utilize a custom assert macro that safely uninstalls all interrupt handlers, but this was not a big deal for this project, so I left this issue unresolved for now.
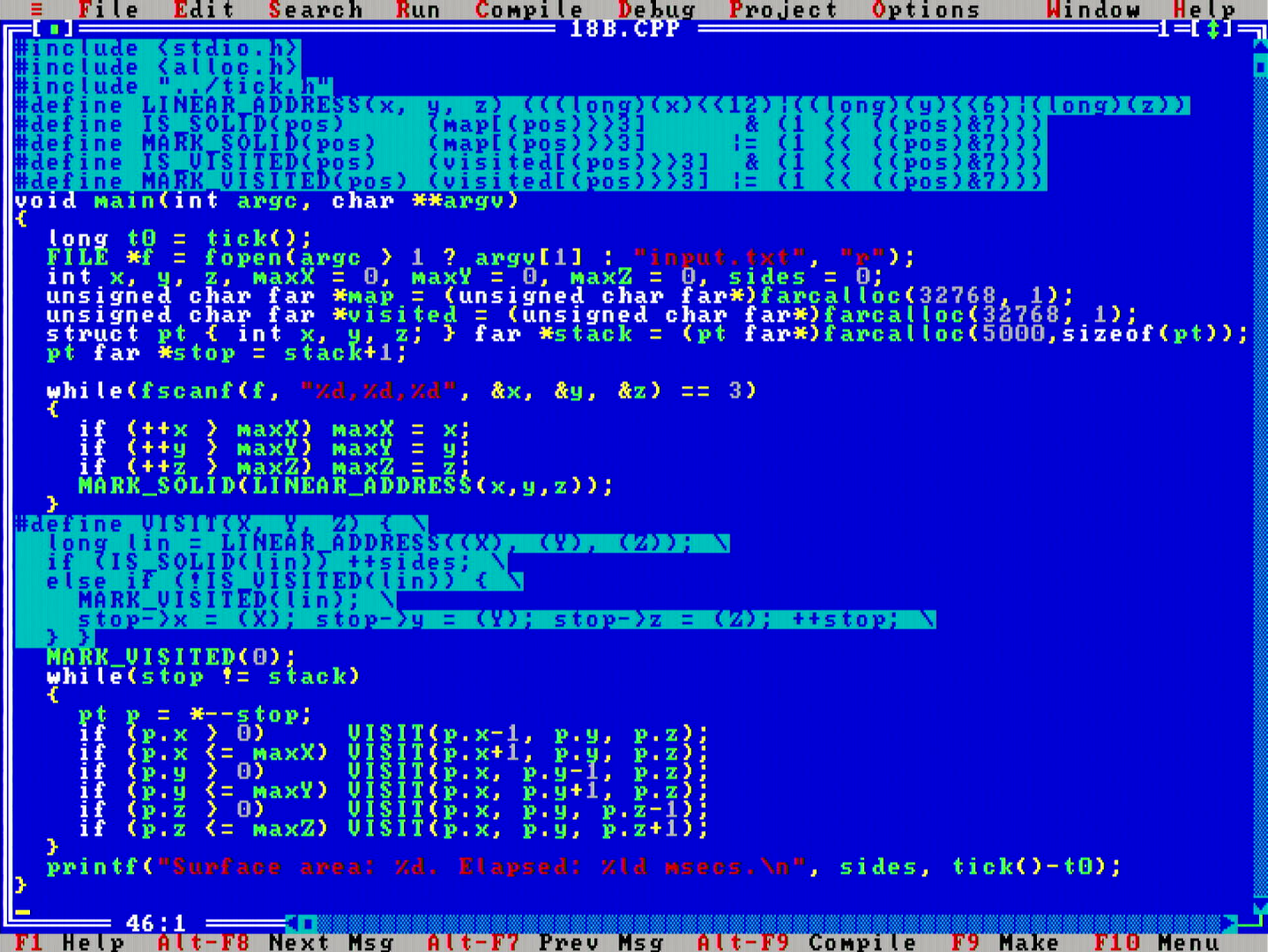
Part 2 asks to exclude the hollow interior points from the count of part 1. This calls for a classic "flood fill" algorithm. The stack-based fill inner loop in the above code is the way that I typically do it, and the simplest way that a flood fill is generally implemented nowadays, although it is remarkable to observe that even this code has suboptimalities that could be sped up by a so called "span-based" flood fill, which is an optimization that reduces the number of redundant stack push-pops and adjacent is-already-filled comparisons. (check out the Flood fill page on Wikipedia for some descriptions).
Twitch.tv video link. Solve time: 54 min 46 seconds. Runtime: part 1: 1853 msecs, part 2: 3656 msecs.
I was completely amazed by the problem on day 19. It seems as if this would be some kind of scheduling problem that should admit a nice solution that works backwards from the end of time, but I wasn't able to come up with anything that smart.
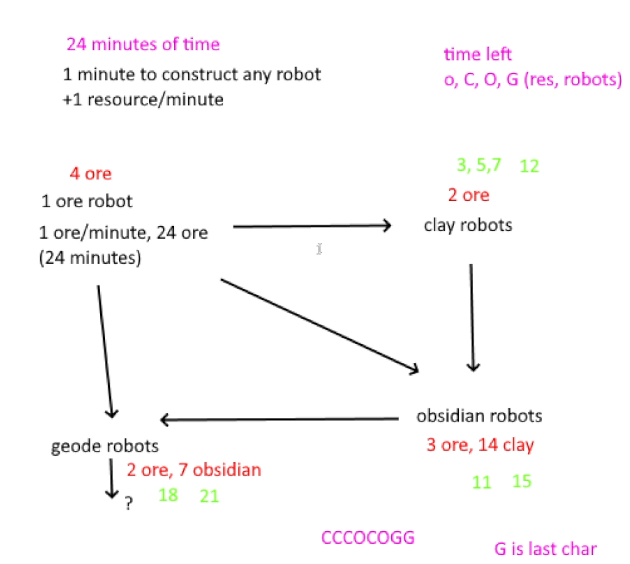
I first spent about an hour to let the problem structure sink in, and drew the above picture.
In the end, I created a simple recursive DFS search with several of either conservative early cutoff rules or suboptimal heuristics. It was really fun to think about these kinds of heuristics, and in the end the resulting computation time was quite manageable.

Nevertheless, I believe my code still runs in a O(5t) time, where t is the number of turns the game is running. Even with such a hard expansion rate, MikroMikko surprisingly completes both parts in a bit over 3 seconds.
Twitch.tv video links: part 1, part 2. Solve time: 1h 1 min 4 seconds on video + maybe 1(?) hour offline. Runtime: part 1: 3574 msecs, part 2: 3256 msecs.
On the problem for day 20 the task is to implement some kind of encoder/decoder mechanism, which shuffles numbers around in a circular list.
This was a problem that really screamed for linked lists, but apparently not loud enough, since I didn't get that from the first read. In hindsight it is obvious, but I did first implement a dumb slow version with regular arrays and memcpy() shifts. After observing there is no way that would ever finish, I re-did it with linked lists.
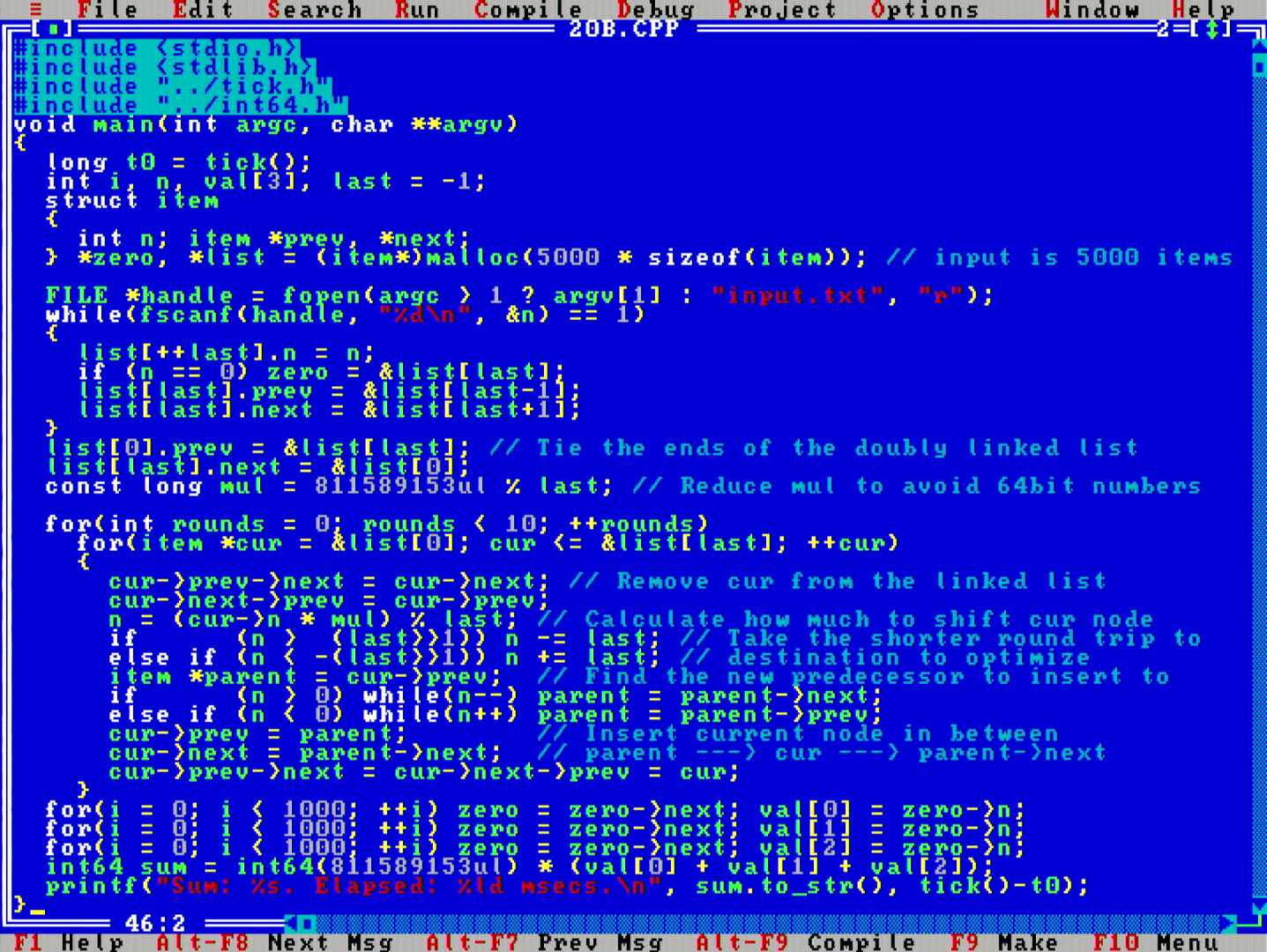
The general property in this problem was to understand that if an item was to be shifted around the circle multiple full rotations, those full rotations can just be reduced away with a modulo operation. (modulo operations also came into play on days 17 and 11, for some reason people on the forums tend to call them "tricks").
In particular notice an important (constant factor) optimization for the 386SX: when one is shifting an element around the circle, if the shift would be going the "long way" around the circle, it is faster to find the same location going the opposite direction on the circle. This almost halved the runtime of the program.
Then with the help of some Christmas magic, I present you:
 ... the final optimized solution! I kid you not, this version runs about 11x faster on the MikroMikko! Note that on my modern Ryzen PC, stress testing these two versions did not find any measurable difference. Goes to show how architectures and compilers have evolved.
... the final optimized solution! I kid you not, this version runs about 11x faster on the MikroMikko! Note that on my modern Ryzen PC, stress testing these two versions did not find any measurable difference. Goes to show how architectures and compilers have evolved.
Why unroll exactly 38 times? Well, it was faster than unrolling only 37 times, and adding any more ->next or ->prev instructions in the chain would cause the compiler to internally run out of memory. (even though it did state that it'd have about 400KB free when it did run out memory.. figures..)
Twitch.tv video link. Solve time: 2 hour 55 min 31 seconds. Runtime: 69.4 seconds.
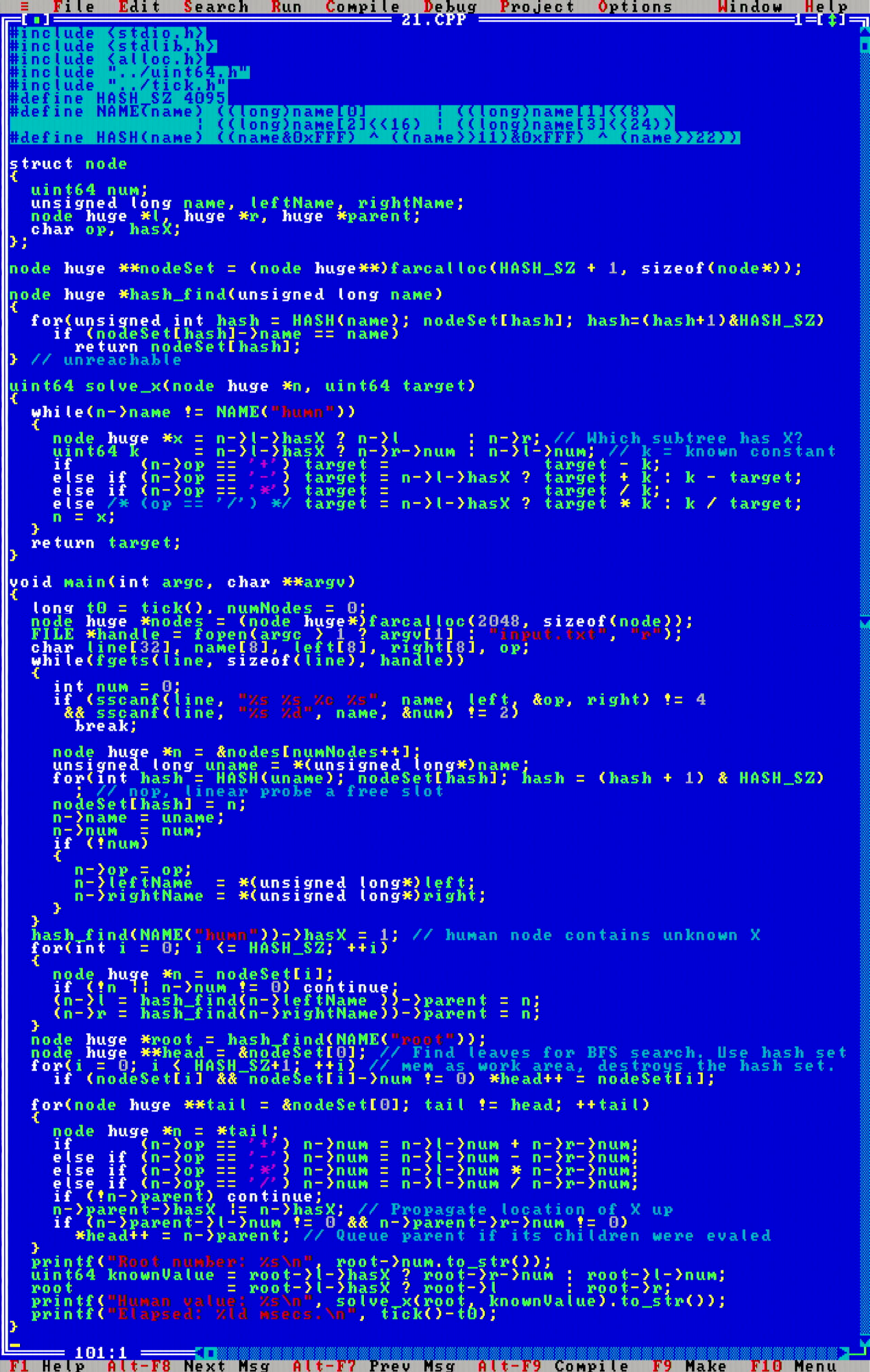 With some improvements to my uint64 class, computation was a breeze. I really like the second part of the problem, as it was one of those that teach you a kind of a "did you know you can do this sort of stuff with that sort of a construction?" type of a problem. Neat!
With some improvements to my uint64 class, computation was a breeze. I really like the second part of the problem, as it was one of those that teach you a kind of a "did you know you can do this sort of stuff with that sort of a construction?" type of a problem. Neat!
Twitch.tv video links: part 1, part 2. Solve time: 3h 8 min 56 seconds on video + maybe 1(?) hour offline. Runtime: 3137 msecs.
After solving this puzzle, I dedicated a day and a half to polish up the UINT64.H header. I tried to make it as complete but compact as possible, but it still came out as a massive 309 lines! Are you ready?
 Phew, implementing a full arithmetic data type in C++ is not a simple task (and there are still shortcomings, such as arithmetic operations only working from one side and not the other). You can find this code in a GitHub repository at juj/UINT64_H, along with a rudimentary test suite. Feel free to use it in your own programs, and remix etc for other purposes.
Phew, implementing a full arithmetic data type in C++ is not a simple task (and there are still shortcomings, such as arithmetic operations only working from one side and not the other). You can find this code in a GitHub repository at juj/UINT64_H, along with a rudimentary test suite. Feel free to use it in your own programs, and remix etc for other purposes.
Today's puzzle was absolutely fantastic. The second part, that is. In the first part the map looked a little bit odd and contrived at first, and I wasn't at all able to connect the dots about why the map looks like the way it does, but in the second part it all naturally made sense.
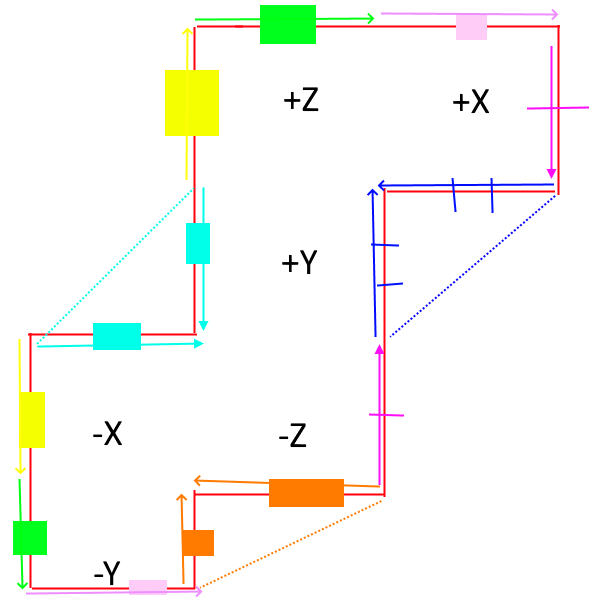
The challenge was to compute a walk on the surface of a 3D cube, that is unfolded to a 2D grid. Like almost everyone, I initially did the hard work and hardcoded the transitions when walking across cube faces. That actually wasn't hard, and scanning back to my video recording, I got only very few bugs from miscomputing the indices. But it was a lot of manual work.
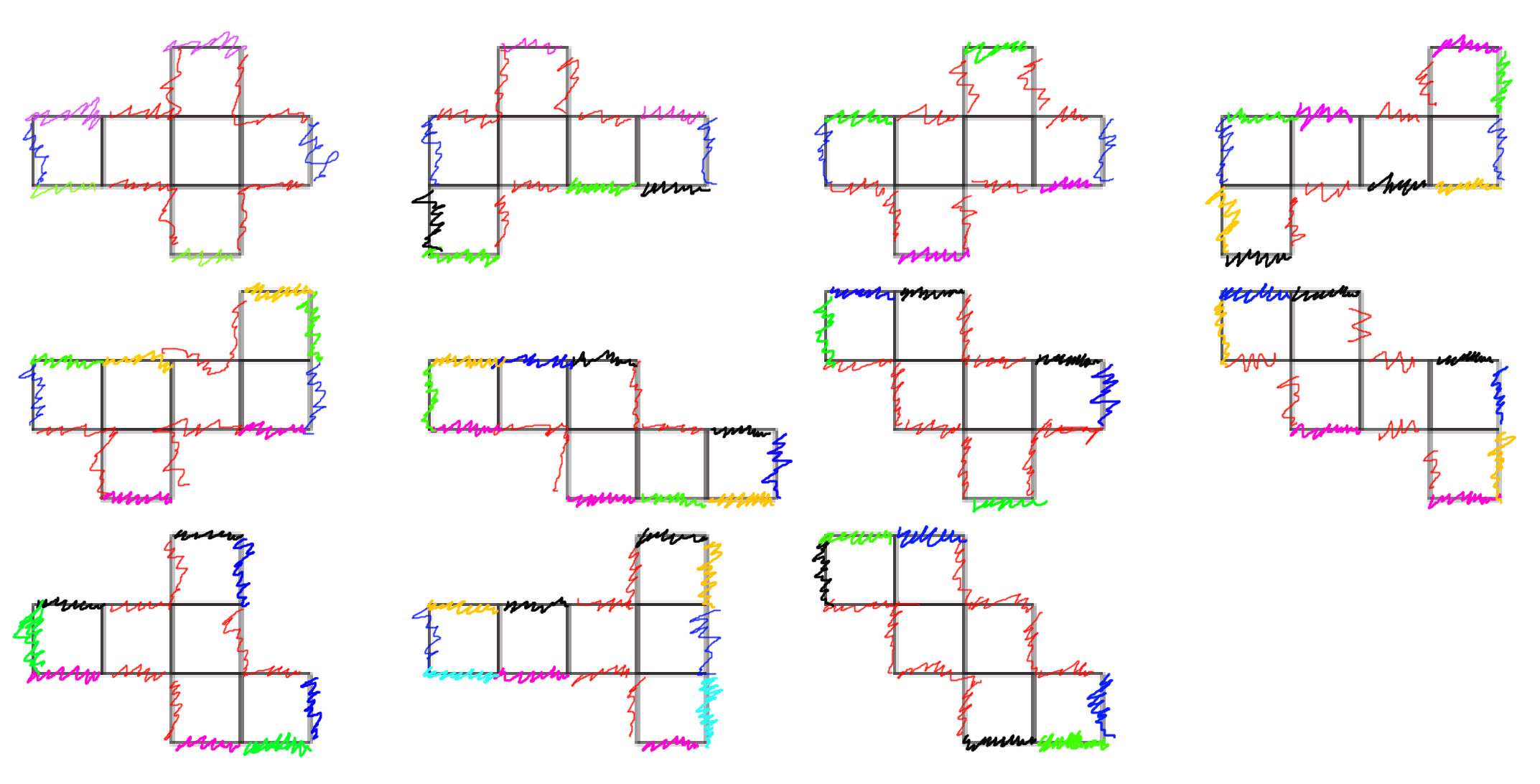
It looks like everyone was given the same unfolded 2D shape for the problem input, which was the 8th one on the list in xy order (the bottom right one). There are actually 11 different ways to unfold a cube.
So the most interesting part of today's challenge was to think about an algorithm for programmatically deducing the cube foldings. I came up with one, and created a set of resources to illustrate the idea if you want to see more:
Final code with hardcoded cube mappings looks like follows.. Quite compact!
Twitch.tv video link. Solve time: 3 hour 11 min 41 seconds. Runtime: part 2: 1920 msecs.
The problem today is a simulation problem like the rope problem from day 9 or the sand fall simulation from day 14. Nothing problematic, although this one does lend itself to different kinds of simulation algorithms, e.g. using 2D hash tables or, if memory is constrained, quadtree maps.
I opted to build a 2D grid where each location would use 4 bits of information: two of these bits store the previous and current elf state, i.e. double-buffered, and two of these bits count whether two or more elves have proposed to move to a given square. Then a two pass algorithm implements the moves.
This algorithm did struggle performance-wise, since there are quite a lot of turns to simulate. My implementation was buggy for a bit and ended with fewer elves on the map than there originally existed. Oops! However after some debugging and 40 minutes of computation time, the correct solution came out. This was the second most compute intensive program so far for the MikroMikko. Runtime Θ(xyt) and space complexity Θ(xy).
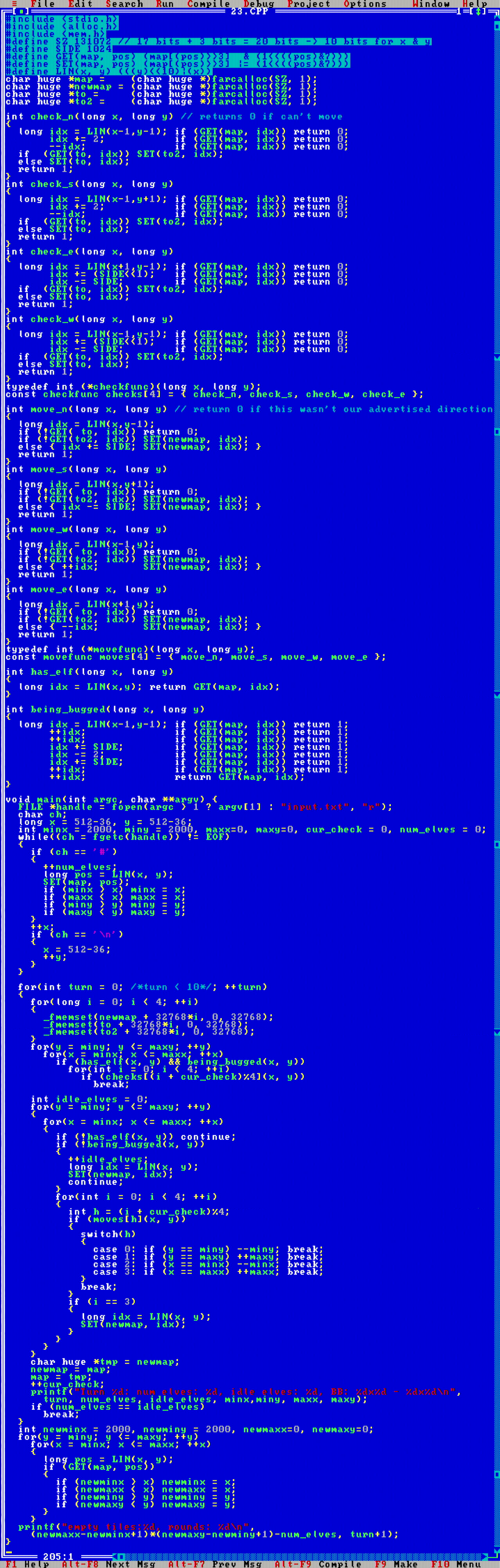 Yikes, the solution ended up being really long.
Yikes, the solution ended up being really long.
Twitch.tv video link. Solve time: 2 hour 56 min 43 seconds. Runtime: 40 minutes.
The eve of Christmas, getting very close to the end. Today we are navigating through a really cold snowstorm, where blizzard rages on a 2D map. Before I saw today's problem, I thought that we would have avoided A* after day 12 already contained a pathfinding problem, but no such luck! So A* ([wikipedia]) it is.
When implementing the A* algorithm, one needs to keep track of two state-containing data structures: open and closed. The open data structure is a priority queue that is ordered on a lower bound cost estimate from the given node to the goal.
The closed data structure on the other hand is a regular unordered set. This represents knowledge of all locations in the state space that have already been searched (and hence should not be looked at again).
The A* search the proceeds to follow a Best First Search according to the cost heuristic of the nodes. It is not particularly a hard concept after having learning about Dijkstra and BFS searches before. However the really tricky part about implementing A* that is often glossed over are the nuances around the decrease-key operation. This operation is needed when a faster path is found to a node that already exists in the open set, so its cost estimate to the goal needs to be decreased. The hard part about this operation is how to identify in the problem state space when this decrease-key operation needs to take place, i.e. how to identify when the same node already exists in the open set, but a shorter path to that node is found afterwards?
Fortunately the way the state space is set up in this problem eliminates the possibility of key decreases from happening. That greatly simplifies the A* implementation in today's problem.
In my implementation I chose to utilize the good old min-heap data structure for the priority queue. Although here I followed the "first make it work, then make it fast" idiom, and initially just implemented a simple insertion sorted linear array as the priority queue. This way I was able to first confirm that my overall search implementation was correct, and only then I replaced the linearly sorted array with the min-heap data structure. Doing things in this order, I was able to confirm that a min heap actually sped up the search (which it should!).
Unfortunately I ran out of time during the video stream. At the 2 hour mark I had the A* search implemented, but had to break off for dinner. Coming back, I opted to finish off the implementation on my Ryzen PC so that I could debug more quickly the different bugs that remained (which there were a few, no surprise). That means that this day marks another day that is similar to day 16, where I would actually not finish implementing the code on the MikroMikko, but I would test and debug it on the Ryzen, and only then bring it back and optimize it to run.
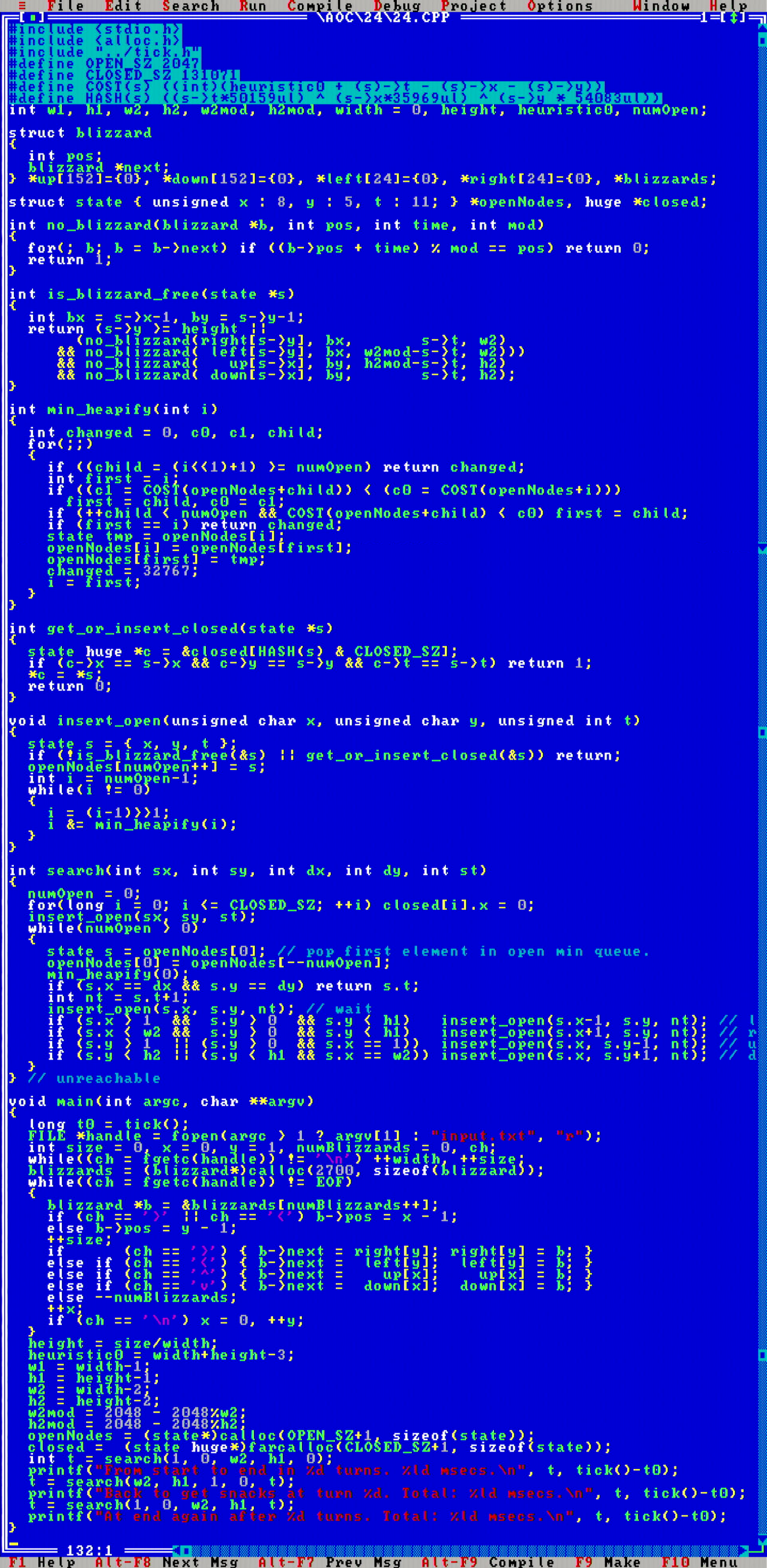
Here is what my final code looks like. After I ran the A* search on the example input and extrapolated the runtime, I was really shocked that this was looking like an eight hour run on the MikroMikko (on Ryzen 5950X it finished in <200 msecs). However, fortunately this was not the case, and the 386SX solves today's problem in about half an hour. Awesome!
If you look at this code in detail, you see it contains a few crucial optimizations. First is this: imagine that each open node would have stored the full 2D blizzard map at time t. This would be on the order of 2700*sizeof({x,y,dir}) bytes of memory, i.e. maybe 10KB at minimum. Then maintaining the open set would have required ~2048*10KB = ~20MB of RAM, which would be completely out of the question.
To work around this memory restriction, the critical observation here is that the blizzards all move linearly with respect to time, so it is actually not necessary to simulate the evolution of the full 2D map state at consecutive turns. Instead, the position of any blizzard can be computed using a single arithmetic expression blizzard_x_pos = (blizzard_start_x_pos + t) % width (with a few plus ones/minus ones to account for the map border conventions). To optimize these calculations, we can further observe that we will statically know by this construction which blizzards could ever be located at any coordinate (x,y) - that is the set of blizzards that either start at column x, or at row y. This way we can prestructure all the blizzards into distinct lists according to which rows and columns those blizzards traverse.
Another optimization relates to the size of the closed data structure. I am using a hash set to implement that data structure. However the number of closed nodes grows really fast during the run. Most of those closed nodes are never again needed as the open boundary of the search progresses. Therefore I opted to forfeit any probing in the hash set implementation, but simply overwrite any previous closed nodes when there is a hash collision. This way accessing the hash set structure remains fast even when its occupancy grows - which it does: with this limited memory amount, occupancy of the closed set was at around 85%-90%, which would kill linear probing performance. (on a PC implementation without memory constraints, this issue would be solved by reallocating more capacity to the hash table so probing accesses would practically not happen)
Final memory usage was 2048*3 = 6KB for the open queue, and 131072*3 = 384KB of memory for the closed set, and ~10.8KB of memory for the static blizzards data structure.
Twitch.tv video link. Solve time: 2 hour 2 min 4 seconds on video plus ~1 hour offline. Runtime: part 1: 7 minutes 3 seconds, part 2: 30 minutes 50 seconds. See also the start of the video from the 25th day for a walkthrough of the above code.
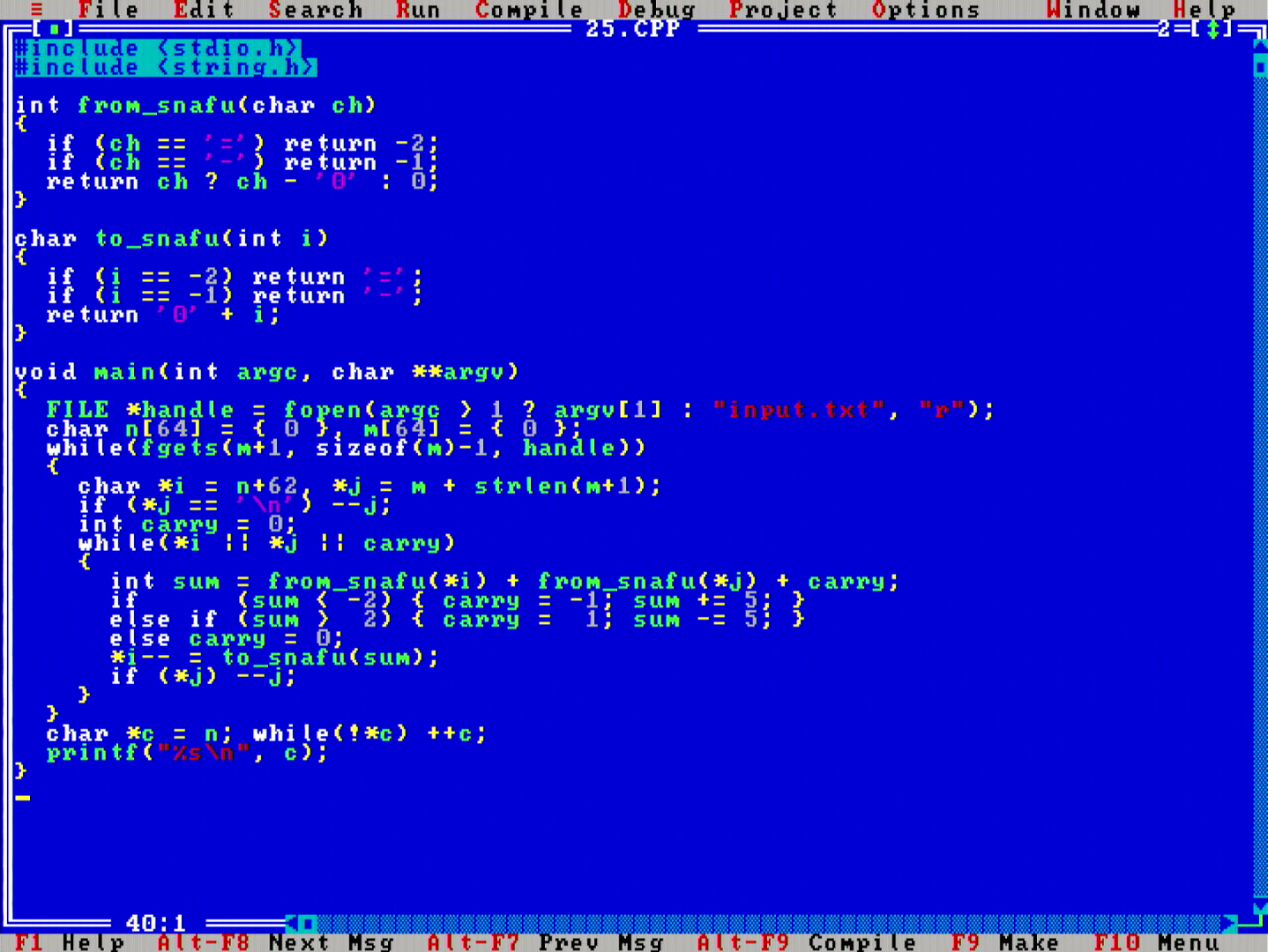
I chose to write a solution that sums the numbers up directly in the SNAFU number system (instead of first converting to decimal, summing, and then converting back). The individual digits do still need to be converted, because MikroMikko does not have hardware support for SNAFU arithmetic. Nevertheless, the inner loop follows the same familiar primary school arithmetic algorithm that we all learn, except that curiously the sign of the carry can go either way!
 Finally all the 50 stars have been collected, Christmas has been saved and snowfall fills the page. I hope you enjoyed following through this ugly Christmas sweater of a web page! :)
Finally all the 50 stars have been collected, Christmas has been saved and snowfall fills the page. I hope you enjoyed following through this ugly Christmas sweater of a web page! :)
Twitch.tv video link. Solve time: 1 hour 18 min 25 seconds. Runtime: 169 msecs.
| Day | Lines of code | Time complexity | Space complexity | MikroMikko runtime | Ryzen 5950X runtime | 386SX/5950X slowdown factor |
| Day 1 | 51 | Θ(n) | Θ(1) | 503msec | 0.146msec | 3445.21x |
| Day 2 | 15 | Θ(n) | Θ(1) | 889msec | 0.4612msec | 1927.58x |
| Day 3 | 20+20 | Θ(n+|A|) | Θ(|A|) | 798msec | 0.3626msec | 2200.77x |
| Day 4 | 13 | Θ(n) | Θ(1) | 957msec | 0.6159msec | 1553.82x |
| Day 5 | 67 | Θ(n) | Θ(n) | 1655msec | 1.2402msec | 1334.46x |
| Day 6 | 15+20 | Θ(n+|A|) | Θ(|A|) | 302msec | 0.311msec | 971.06x |
| Day 7 | 71 | Θ(n) | Θ(n) | 732msec | 1.5441msec | 474.06x |
| Day 8 | 23+26 | Θ(xy) | Θ(xy) | 2306msec | 0.4684msec | 4923.14x |
| Day 9 | 45 | Θ(n) | Θ(xy) | 2885msec | 0.7624msec | 3784.10x |
| Day 10 | 43 | Θ(n) | Θ(1) | 75msec | 0.1414msec | 530.41x |
| Day 11 | 45 | Θ(n) | Θ(n) | 4min 14s | 2.7645msec | 91879.18x |
| Day 12 | 58 | Θ(xy) | Θ(xy) | 340msec | 0.1617msec | 2102.66x |
| Day 13 | 45 | Θ(n) | Θ(1) | 682msec | 0.2724msec | 2503.67x |
| Day 14 | 66 | Θ(n) | Θ(xy) | 4982msec | 0.8159msec | 6106.14x |
| Day 15 | 75 | Θ(n*√n*logn) | Θ(n) | 112msec | 0.1879msec | 596.06x |
| Day 16 Part 1 | - | O(n!) | O(n!) | 24700msec | 4.5213msec | 5463.03x |
| Day 16 Part 2 | 106 | O(n!) | O(n!) | 80min | 216.323msec1 | 22189.04x1 |
| Day 17 | 103 | Θ(n) | Θ(n) | 25900msec | 4.2336msec | 6117.72x |
| Day 18 | 28+45 | Θ(n+xyz) | Θ(n) | 5509msec | 2.05msec | 2687.32x |
| Day 19 Part 1 | - | O(5t) | Θ(1) | 3574msec | 0.8598msec | 4156.78x |
| Day 19 Part 2 | 147 | O(5t) | Θ(1) | 3256msec | 0.4705msec | 6920.30x |
| Day 20 | 46/82 | Θ(n²) | Θ(n) | 69418msec | 104.8814msec | 661.87x |
| Day 21 | 100 | Θ(n) | Θ(n) | 3137msec | 2.0963msec | 1496.45x |
| Day 22 | 83 | Θ(xy+n) | Θ(xy) | 1920msec | 0.3641msec | 5273.28x |
| Day 23 | 204 | Θ(xyt) | Θ(xy) | 40min | 91.0598msec | 26356.31x |
| Day 24 | 131 | O(xyt) | O(xyt) | 30min 50sec | 168.1978msec | 2306.81x |
| Day 25 | 39 | Θ(n) | Θ(1) | 169msec | 0.1298msec | 1302.00x |
| Total | 1750(2) | - | - | 9434.101 seconds | 605.443 msecs | 15582.15x1 |
1The timing on day 16 part 2 is done when using unbounded amount of memoization cache (~22.11MB) on the Ryzen. If we constrain Ryzen to only use the same amount of memory as MikroMikko would use (<768KB), it would finish in 647.1044 msecs, and the respective 386/Ryzen performance factor would be "only" 7417.66x (and the Total performance difference on the last row would be 9104.52x)
2In this count I left out the lines of code taken up by the general UINT64.H header (+308 lines of code), and the TICK.H header (+72 lines of code).
The computationally hardest days were days 16, 19, 23 and 24. The final solution on day 19 was quite fast, though getting there took a lot of computation.
Looking at the speed difference between Ryzen 5950X and 386SX, it typically ranges between being 1000x-5000x slower. The outlier on day 11 is explained by the very modulo operator heavy arithmetic in the inner loop, and the outlier on day 16 part 2 is due to the difference in available memory. Although I don't actually have an answer why day 23 solution is so much slower on the MikroMikko compared to the Ryzen.
If we disregard day 16 part 2 memory difference, then the average 9104.52x speedup factor can be interpreted in another way: clock-for-clock, the AMD Ryzen 5950X "feels like" a 145.664 GHz clocked Intel 386SX CPU. :D
Digging into MS-DOS Borland Turbo C++ 3.0 real mode programming for the first time again in ~25 years was a heartwarming experience, and I am not gonna lie, made me tear up a few times. I absolutely love navigating these kinds of text mode menus with ASCII art. I also loved the sound of the floppy disk drive crunching every morning while I was sipping my morning coffee.
DOS programming is so much simpler in some ways compared to modern times. VGA graphics framebuffers access in comparison to modern graphics, oh man. Programming on the MikroMikko was also quite a different experience than what I would have expected, and in some ways drastically unlike what I had anticipated. Here are the main ones:
First, it is interesting to realize how much productivity difference there is only in "soft" improvements in computing software. Comparing the Turbo C++ IDE to e.g. Sublime Text or Visual Studio, many of the improvements in how a programming text editor works are the source of a large amount of convenience, which results in time saving productivity.
With Turbo C++, I can feel how I am really "operating" the editor. It is like driving without having power steering in your car. For example, I'd love to simply have Ctrl-C, Ctrl-X, Ctrl-V shortcuts in the Borland IDE, instead of having to use more awkward, Ctrl-Ins, Ctrl-Del and Shift-Ins shortcuts. Also the way the text selection cursor works in Turbo C++ is awkward, and there is no support for multiline indenting with Tab/Shift-Tab, but pressing Tab while text is selected will replace the selected block with the Tab character. There is no alt-tab either, and searching and search-replacing is tedious. Likewise, the simple feature in text editors where when you either select, or double-click a piece of text, the IDE will highlight all occcurrences of that text, makes a world of a difference in productivity.
The remarkable part is that there is no reason why an ancient DOS text editor could not have any of these, but nobody just thought of those ideas back then.
Another surprise was about the speed of the 16MHz CPU. At the start of the month, I thought that this would have been the biggest pressure, and that computation times in these challenges would have gotten absolutely ridiculous to be practical. However, turns out that this was not the case, the old 386SX had no problem to produce the solutions for each day.
Although instead of concluding "386SX-16MHz is not that slow", I think the more appropriate conclusion is to congratulate Eric Wastl for well designed puzzle constructs that did not blow out of hand. He really understands the workloads that he is proposing, and makes good decisions on what kind of problem sizes to produce.
The part where slow CPU speed did become a problem was in productivity, in two different ways:
What was also interesting is how two other issues: lack of 64-bit numbers and lack of memory in real mode caused more time struggle than lack of CPU speed. I spent around ~two days creating a uint64 emulation class and the related arithmetic. This is actually not the first time, and not even the second time (most recently when I worked on emulating 64-bit ops was with the asm.js technology, which also did not have 64-bit integers), though since that is one of those aspects that one rarely actively needs, it is a time sink to do (but I admit, a lot of fun :D).
Likewise, dabbling into EMS, XMS, UMB and HMA memory specs was a lot of fun, maybe I'll revisit those at some point.
Although ultimately, I think it is now time to retire the Borland Turbo C++ 3.0 compiler box where it belongs, on the top spot in my bookshelf, to remind me of the history where it all started from for me.
Signing off for the year,
Some Mug
P.S. If you got this far, here is my Christmas present to you.
Here you can find links to the different maybe useful resources that were built alongside this challenge: